Sebastian Raschka (@rasbt)
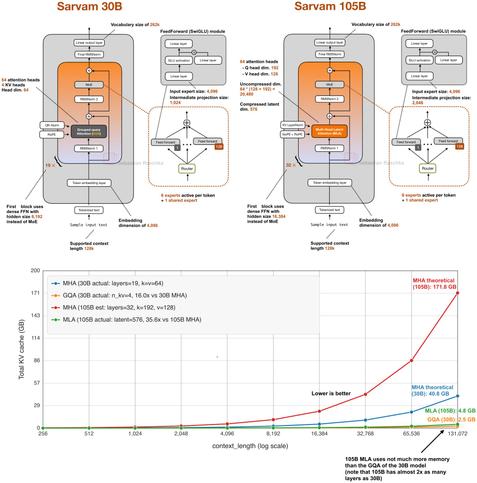
DeepSeek V4를 기다리는 가운데 인도에서 두 가지 강력한 오픈-웨이트 LLM이 공개되었습니다. Sarvam 30B와 Sarvam 105B로, 둘 다 추론에 특화된 모델이며 특히 작은 30B 모델은 전통적 Grouped Query Attention(GQA)를 사용합니다. 오픈-웨이트 공개로 연구자와 개발자가 즉시 실험·활용할 수 있다는 점이 주목됩니다.
Sebastian Raschka (@rasbt) on X
While waiting for DeepSeek V4 we got two very strong open-weight LLMs from India yesterday. There are two size flavors, Sarvam 30B and Sarvam 105B model (both reasoning models). Interestingly, the smaller 30B model uses “classic” Grouped Query Attention (GQA), whereas the