N8 Programs (@N8Programs)
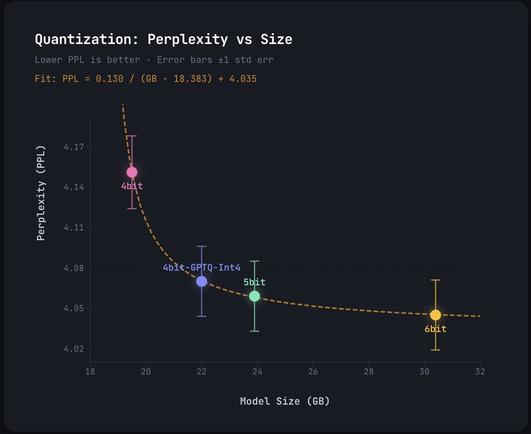
Alibaba의 Qwen 모델용 GPTQ Int4 가중치를 dequant/requant 없이 직접 MLX 형식으로 변환하여 MLX 런타임과 호환되도록 패킹함. 결과물은 동일한 Hugging Face(HF) 가중치를 기반으로 하나 Qwen의 양자화는 어텐션 레이어와 임베딩을 비양자화로 남겨 표준 MLX 4비트 양자화보다 파일 크기가 약간 더 큼.
N8 Programs (@N8Programs) on X
Converted @Alibaba_Qwen's GPTQ Int4 to MLX directly, w/out dequant/requant - so its the same HF weights but now packed to be compatible w/ MLX runtime. Lands slightly larger than a standard MLX 4-bit quant as the Qwen quant leaves attention layers + embeddings unquantized.

