Decoupled DiLoCo: Resilient, Distributed AI Training at Scale
https://deepmind.google/blog/decoupled-diloco/
#HackerNews #DecoupledDiLoCo #ResilientAI #DistributedTraining #AIatScale #DeepMind
Decoupled DiLoCo: Resilient, Distributed AI Training at Scale
https://deepmind.google/blog/decoupled-diloco/
#HackerNews #DecoupledDiLoCo #ResilientAI #DistributedTraining #AIatScale #DeepMind
Omar Sanseviero (@osanseviero)
대규모 분산 학습을 위한 새로운 접근법인 Decoupled DiLoCo가 소개되었습니다. 저대역폭 환경에서 전 세계적으로 분산된 설정으로 학습할 수 있어, 대규모 모델 학습 효율을 크게 높일 수 있는 유망한 기술로 보입니다. 후속 연구와 산업 적용 가능성이 기대됩니다.
https://x.com/osanseviero/status/2047409450424922173
#distributedtraining #largescaleai #deeplearning #openresearch #llm
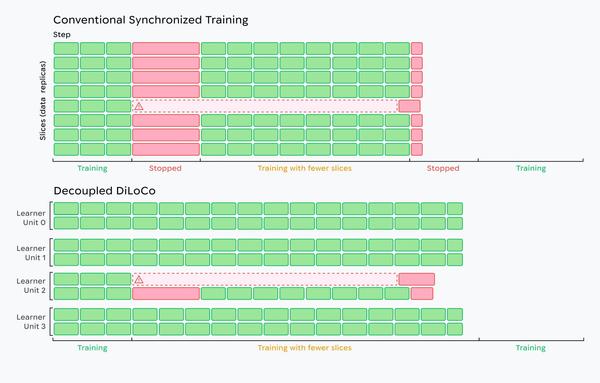
Introducing Decoupled DiLoCo, a breakthrough in large scale distributed training Low bandwidth way of training globally in a distributed setup. DiLoCo and follow-up works can be quite game changing in the industry and I'm very excited to see how they evolve
Google DeepMind (@GoogleDeepMind)
새로운 분산 AI 모델 학습 방식인 Decoupled DiLoCo를 소개했다. 여러 데이터센터에 걸쳐 고급 AI 모델을 더 탄력적이고 유연하게 학습할 수 있도록 설계된 기술로, 대규모 분산 학습 인프라와 모델 훈련 효율성 개선에 중요한 의미가 있다.
https://x.com/GoogleDeepMind/status/2047330981145669790
#distributedtraining #aimodels #multidatacenter #machinelearning
Arthur Douillard (@Ar_Douillard)
Google DeepMind와 Google Research가 분산·이기종 하드웨어 환경에서도 시스템을 멈추지 않고 대규모 사전학습을 수행할 수 있는 새로운 훈련 방식 Decoupled DiLoCo를 공개했다. 전 세계 데이터센터를 활용하는 탄력적인 AI pre-training을 목표로 하며, 확장성과 안정성을 크게 높일 수 있는 기술이다.
https://x.com/Ar_Douillard/status/2047329942547968171
#googledeepmind #googleresearch #pretraining #ai #distributedtraining

The DiLoCo team at Google DeepMind and Google Research is proud to release Decoupled DiLoCo, the next frontier for resilient AI pre-training. Decoupled DiLoCo enables training with datacenters across the world, using heterogeneous hardware, and never halting the system despite
Alex Cheema (@alexocheema)
AMD Ryzen AI Max+ 시스템 클러스터에서 텐서 병렬화(tensor parallelism)를 성공적으로 운용한 사례를 묻는 질문형 트윗. 작성자는 소프트웨어 지원이 부족하다는 이야기를 들었다며, 왜 그런지와 실제 동작 사례를 궁금해하고 있음.
Akshay (@akshay_pachaar)
딥러닝 모델은 기본 설정으로는 여러 GPU가 있어도 보통 단일 GPU만 사용한다는 지적. 이상적인 학습은 학습 부하를 여러 GPU에 분산하는 것이라며, 다중 GPU 훈련을 위한 네 가지 전략을 그래픽으로 소개한다는 내용(멀티-GPU 분산 학습 기법 소개).

By default, deep learning models only utilize a single GPU for training, even if multiple GPUs are available. An ideal way to train models is to distribute the training workload across multiple GPUs. The graphic depicts four strategies for multi-GPU training👇
Avi Chawla (@_avichawla)
Multi-GPU 트레이닝을 위한 4가지 전략을 시각 자료로 설명한 게시물입니다. 대규모 모델 학습에서의 병렬화·데이터/모델 분할·메모리 최적화 등 다양한 멀티-GPU 접근법을 한눈에 비교해 이해를 돕는 내용으로 보입니다.







