Claude Code 세션 관리 전략, 1M 컨텍스트 시대에 달라진 것들
Claude Code에서 1M 컨텍스트 시대 세션 관리 전략. Continue·Rewind·Compact·Clear·Subagents를 언제 써야 하는지 Anthropic 공식 설명으로 정리했습니다.
Claude Code 세션 관리 전략, 1M 컨텍스트 시대에 달라진 것들
Claude Code에서 1M 컨텍스트 시대 세션 관리 전략. Continue·Rewind·Compact·Clear·Subagents를 언제 써야 하는지 Anthropic 공식 설명으로 정리했습니다.Claude Code vs Pi, 같은 작업에서 토큰 사용이 10배 차이 나는 이유
Claude Code와 Pi를 같은 작업으로 비교했더니 토큰 소비가 10배 차이. 에이전트가 자기 자신에게 쓰는 하네스 세금 개념을 설명합니다.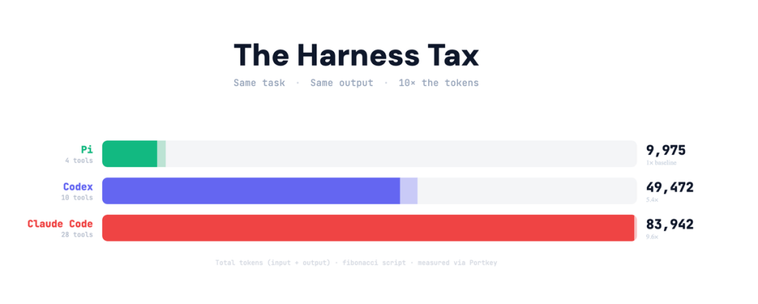
TIL You can respawn context point and parallelize #vibecoding development to avoid #contextrot or explore alternative pathways with /rewind
I think I just leveled up my vibecoding, can't wait to try it!
긴 컨텍스트 LLM의 숨겨진 함정, Context Rot 현상과 RLM 해결책
긴 컨텍스트를 처리할 때 LLM 성능이 저하되는 Context Rot 현상과, 이를 해결하는 RLM(Recursive Language Model) 접근법을 소개합니다.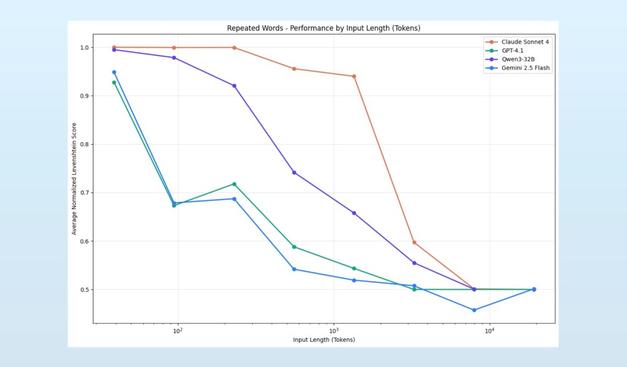
Spotify wprowadza inżynierię kontekstu – nowa era dla agentów kodujących
Czy agent może w tle przepisać tysiące repozytoriów, nie gubiąc wątku po drodze i bez pytania „a o co chodziło? ” co kilka minut?
Czytaj dalej:
https://pressmind.org/spotify-wprowadza-inzynierie-kontekstu-nowa-era-dla-agentow-kodujacych/
#PressMindLabs #agencikodujacy #claudecode #contextrot #deepagents #inzynieriakontekstu

Theo dõi 847 lượt chạy agent (Llama 3.1 70B, Qwen 2.5 72B) phát hiện “context rot” khi ngữ cảnh >60‑70%: độ tuân lệnh giảm từ 94% xuống 41%, vi phạm ràng buộc lên tới 31.7%. Giải pháp: nén aggressive, snapshot trạng thái, chia task thành các context riêng. Đã mở mã nguồn công cụ quản lý context. #AI #LLM #ContextRot #MachineLearning #TríTuệNhânTạo #OpenSource
https://www.reddit.com/r/LocalLLaMA/comments/1qio9nj/i_tracked_context_degradation_across_847_agent/
LLM이 컨텍스트 윈도우 100배를 처리한다: MIT의 Recursive Language Models
MIT CSAIL의 Recursive Language Models(RLM)은 LLM이 컨텍스트 윈도우 100배 규모의 입력을 처리하도록 합니다. 프롬프트를 환경 변수로 취급하고 재귀 호출로 1,000만 토큰 이상을 효율적으로 다루는 혁신적 추론 전략입니다.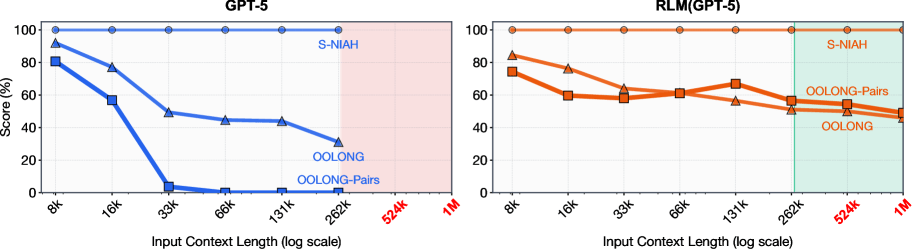
Anthropic Challenges OpenAI with 1M Token Claude Sonnet 4 Upgrade, But Is Bigger Always Better?
#AI #LLM #Anthropic #Claude4Sonnet #Claude4 #OpenAI #GPT5 #ContextWindow #ContextRot

‘Context Rot’: New Study Reveals Why Bigger Context Windows Don't Magically Improve LLM Performance
#AI #LLM #ContextRot #MachineLearning #AIResearch #ContextWindow #Gemini25Pro #GoogleGemini

"Large Language Models (LLMs) are typically presumed to process context uniformly—that is, the model should handle the 10,000th token just as reliably as the 100th. However, in practice, this assumption does not hold. We observe that model performance varies significantly as input length changes, even on simple tasks.
In this report, we evaluate 18 LLMs, including the state-of-the-art GPT-4.1, Claude 4, Gemini 2.5, and Qwen3 models. Our results reveal that models do not use their context uniformly; instead, their performance grows increasingly unreliable as input length grows.
Recent developments in LLMs show a trend toward longer context windows, with the input token count of the latest models reaching the millions. Because these models achieve near-perfect scores on widely adopted benchmarks like Needle in a Haystack (NIAH) [1], it’s often assumed that their performance is uniform across long-context tasks.
However, NIAH is fundamentally a simple retrieval task, in which a known sentence (the “needle”) is placed in a long document of unrelated text (the “haystack”), and the model is prompted to retrieve it. While scalable, this benchmark typically assesses direct lexical matching, which may not be representative of flexible, semantically oriented tasks.
We extend the standard NIAH task, to investigate model behavior in previously underexplored settings. We examine the effects of needles with semantic, rather than direct lexical matches, as well as the effects of introducing variations to the haystack content.
(...)
We demonstrate that even under these minimal conditions, model performance degrades as input length increases, often in surprising and non-uniform ways. Real-world applications typically involve much greater complexity, implying that the influence of input length may be even more pronounced in practice."
