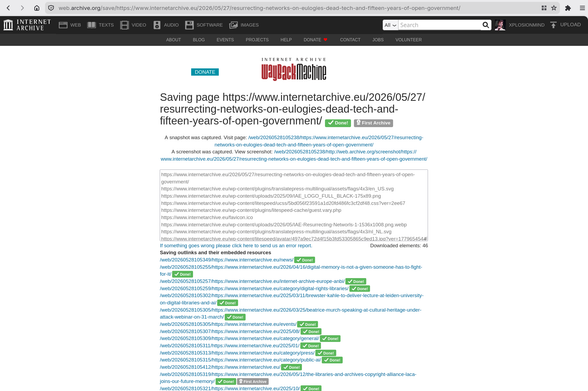
seen on HN: https://kage.tamnd.com/
kage renders every page in headless Chrome, snapshots the final DOM, removes every script and event handler, and downloads and rewrites the CSS, images, and fonts.
saves in ZIM Format, in the comments the author says it will support WARC too https://news.ycombinator.com/item?id=48529990