RE: https://openbiblio.social/@nabatz/116595622896548036
fyi #bibliocon26 - to whom it may concern #ZDB #sparql
RE: https://openbiblio.social/@nabatz/116595622896548036
fyi #bibliocon26 - to whom it may concern #ZDB #sparql
Just published a nanopublication to list all other nanopubs mentioning the Snakemake Workflow Management System: https://w3id.org/np/RAzeQbv1gXqKIuLic4xTP1gYRnL4YhU_5oRl62nbNl2Xk
Not yet sophisticated, but I am starting to like #SparQl 😉
@julbriman @lessanspages @ledeuxiemetexte
@sukkoria
ok, avec une requête #SPARQL à l'arrache, j'en sors 10000 (avec image) sans douleur... - et je me suis contentée des "écrivaines"
c'est pas le choix qui manque :D
Seit Anfang 2025 habe ich mich auf Anregung von @vermessungsbibliothek etwas mehr mit #Wikidata beschäftigt: Hauptsächlich als Schlagworte für mein persönliches Blog, die dann beispielsweise in anderen Metadatenformaten (#Schema.org, #LinkedArt) zum Einsatz kommen.
Nun können diese Daten auch für Recherchen genutzt und #SPARQL-Abfragen verwendet werden. Vielleicht ist das eine Weltneuheit für statische Webseiten.
SASSY has hit a wall, part 2.
The rule engine uses SPARQL to find the data the rules are to be applied to. Blank nodes break this design.
When I first started SASSY I avoided blank nodes. As time went on I realised that generated names for nodes was going to save a lot of time, so I used them in lists and other places where names did not add any real information to the model.
My initial design for generated names was OK for toy examples, but was not going to work well for a multi-user distributed system. Hence I moved to using blank nodes that have identifiers which are mini-UUIDs.
So the early version of the rule engine worked OK since it used generated names. It is only the more recent data that uses the blank nodes, and the world fell apart.
2/n
I had a lot of fun implementing a SPARQL editor for DanNet. During this process I also wrote a ton of new documentation, including a SPARQL tutorial that uses the new editor for its interactive examples.
The idea is, of course, to make the Danish WordNet more broadly accessible. Previously, you would have had to spin up your own RDF triplestore to query DanNet using SPARQL.
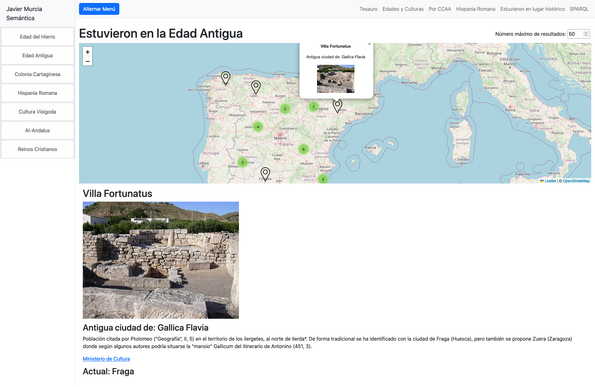
¿Puede un algoritmo "deducir" a qué ciudad antigua perteneció un monumento?
En mi proyecto de Toponimia Histórica de España construí una consulta en SPARQL que generó automáticamente más de 2.500 posibles emparejamientos.
La conclusión inferida por el Grafo: Es altamente probable que ese resto arqueológico estuviera situado en aquel asentamiento histórico.
Demo [https://javiermurcia.tech/lab/toponimia-historica/monumento-estuvo-en-lugar-historico.html]
#DataScience #Ontologias #SPARQL #DataEngineering #SemanticWeb