
Robust penalized estimators for high-dimensional generalized linear models - TEST
Robust estimators for generalized linear models (GLMs) are not easy to develop due to the nature of the distributions involved. Recently, there has been growing interest in robust estimation methods, particularly in contexts involving a potentially large number of explanatory variables. Transformed M-estimators (MT-estimators) provide a natural extension of M-estimation techniques to the GLM framework, offering robust methodologies. We propose a penalized variant of MT-estimators to address high-dimensional data scenarios. Under suitable assumptions, we demonstrate the consistency and asymptotic normality of this novel class of estimators. Our theoretical development focuses on redescending $$\rho $$ ρ -functions and penalization functions that satisfy specific regularity conditions. We present an Iterative re-weighted least-squares algorithm, together with a deterministic initialization procedure, which is crucial since the estimating equations may have multiple solutions. We evaluate the finite-sample performance of this method for Poisson distribution and well-known penalization functions through Monte Carlo simulations that consider various types of contamination, as well as an empirical application using a real dataset.
I am surprised this paper received so little attention. It dramatically reduces RAM requirements for very big
#statistical #generalizedlinearmodels while offering
#computational speed ups ~x500. A
#recommender system used it in a
#neuralnetwork with
#tensorflow to get substantial time & memory savings.
https://arxiv.org/abs/2205.13080Languages with
#array/
#tensor features should take note, as this is a serious contender to sparse matrix computations
#datascience #machinelearninghttps://mstdn.science/@ChristosArgyrop/110934217550435224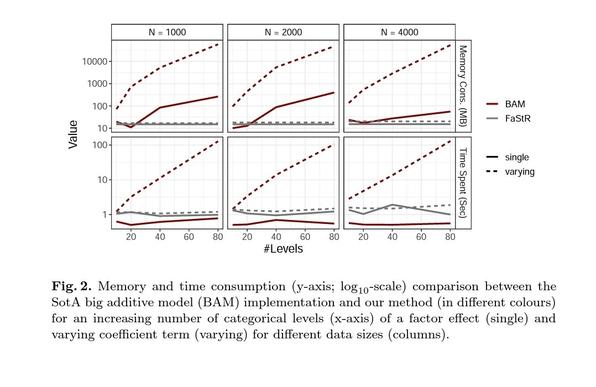

Factorized Structured Regression for Large-Scale Varying Coefficient Models
Recommender Systems (RS) pervade many aspects of our everyday digital life.
Proposed to work at scale, state-of-the-art RS allow the modeling of thousands
of interactions and facilitate highly individualized recommendations.
Conceptually, many RS can be viewed as instances of statistical regression
models that incorporate complex feature effects and potentially non-Gaussian
outcomes. Such structured regression models, including time-aware varying
coefficients models, are, however, limited in their applicability to
categorical effects and inclusion of a large number of interactions. Here, we
propose Factorized Structured Regression (FaStR) for scalable varying
coefficient models. FaStR overcomes limitations of general regression models
for large-scale data by combining structured additive regression and
factorization approaches in a neural network-based model implementation. This
fusion provides a scalable framework for the estimation of statistical models
in previously infeasible data settings. Empirical results confirm that the
estimation of varying coefficients of our approach is on par with
state-of-the-art regression techniques, while scaling notably better and also
being competitive with other time-aware RS in terms of prediction performance.
We illustrate FaStR's performance and interpretability on a large-scale
behavioral study with smartphone user data.