Big Tech said building ethical AI was “impossible.” They were wrong.
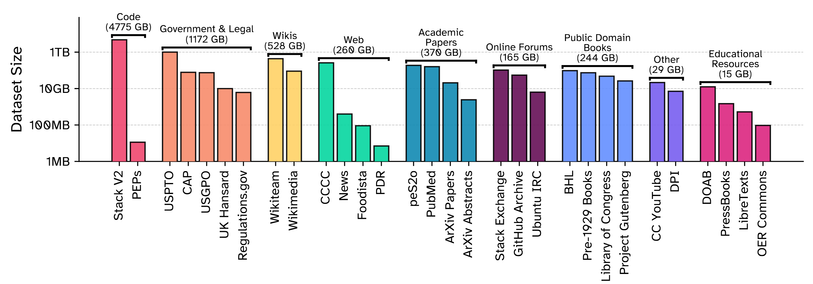
Meet Common Pile v0.1 — an 8TB dataset built entirely from public domain & openly licensed data by a grassroots team from MIT, Cornell & beyond. No shady scraping. No excuses.
They proved: it’s not about possibility, it’s about effort.
#AI #EthicalAI #DataEthics #OpenSource #TechForGood #CommonPile #MachineLearning #Transparency #FutureOfAI