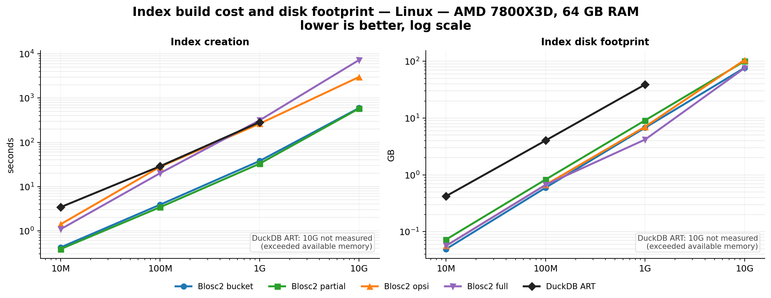
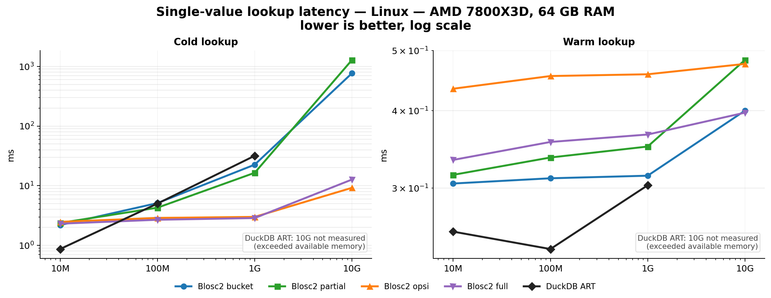
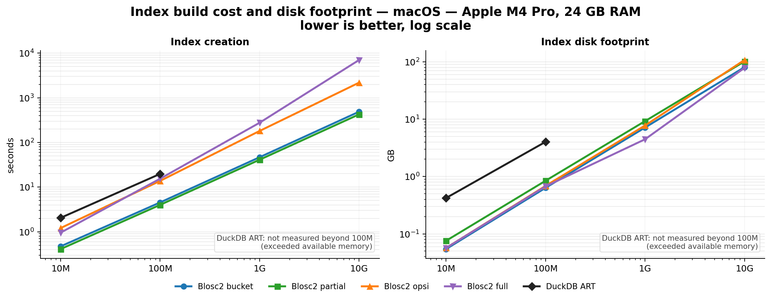
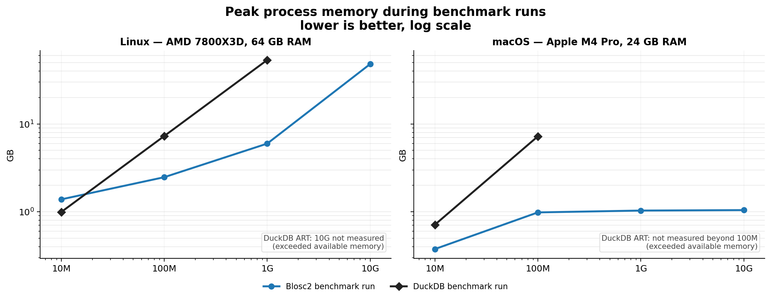
📰 Oh, look! A 12-minute read on how #TimescaleDB compresses data, because obviously, everyone has time to delve into the wonders of #Hypercore and Columnar Storage. 🤔 But hey, if watching paint dry isn't your style, imagine the thrill of squeezing data "up to 98" – whatever that means! 🙄
https://roszigit.com/en/blog/timescaledb-compression-hypercore #DataCompression #ColumnarStorage #TechTrends #HackerNews #ngated
https://roszigit.com/en/blog/timescaledb-compression-hypercore #DataCompression #ColumnarStorage #TechTrends #HackerNews #ngated