StepFun (@StepFun_ai)
StepAudio 2.5 TTS가 @ArtificialAnlys Speech Arena에서 중국 TTS 모델 중 1위, 전 세계 기준 Top 3를 기록했다고 밝힌 트윗입니다. 블라인드 테스트와 실제 청취 평가에서 높은 성과를 얻은 것으로, 음성 합성 모델의 성능 경쟁에서 주목할 만한 신제품 발표입니다.
StepFun (@StepFun_ai)
StepAudio 2.5 TTS가 @ArtificialAnlys Speech Arena에서 중국 TTS 모델 중 1위, 전 세계 기준 Top 3를 기록했다고 밝힌 트윗입니다. 블라인드 테스트와 실제 청취 평가에서 높은 성과를 얻은 것으로, 음성 합성 모델의 성능 경쟁에서 주목할 만한 신제품 발표입니다.
Lucas Meijer (@lucasmeijer)
Gemini TTS의 음성 품질이 매우 좋다고 언급하며, 3분 분량의 긴 텍스트를 여러 청크로 나눠 처리할 때 구간마다 목소리 특성이 달라지는 문제를 지적한다. 긴 음성 합성에서 일관성을 유지하는 방법을 질문하는 내용으로, 구글의 TTS 기술 활용 이슈를 보여준다.
Artificial Analysis (@ArtificialAnlys)
Suno가 최신 음악 생성 모델 V5.5를 공개했다. Artificial Analysis의 Instrumental과 Vocals 리더보드에서 모두 1위를 차지하며 이전 V5 대비 성능이 크게 향상됐다. 함께 개인화와 관련된 3가지 새로운 기능도 출시되어 음악 생성 AI 제품의 경쟁력을 높였다.
https://x.com/ArtificialAnlys/status/2049984010282217688
#suno #musicgeneration #audiomodel #artificialanalysis #generativeai
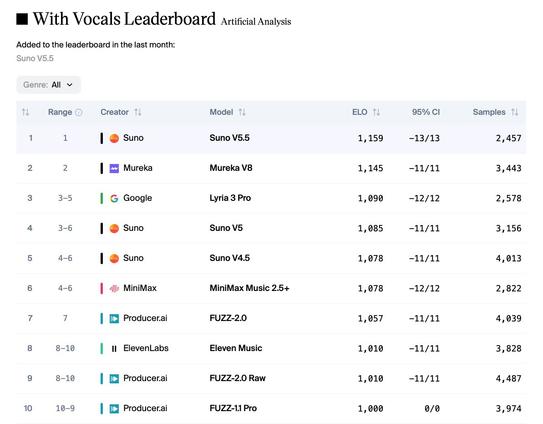
Suno V5.5 lands at #1 on both the Artificial Analysis Instrumental and Vocals Leaderboards, a notable improvement over Suno's previous V5 model! Suno V5.5 is the latest music generation model from @Suno, released alongside three new features that focus on personalization and
Bindu Reddy (@bindureddy)
비디오와 이미지용 에이전틱 오케스트레이션을 발표했다. GPT 5.5와 Opus 4.7 에이전트가 최적의 비디오·오디오 모델을 조율하며, Grok Imagine, Nano Banana Pro, SeeDance 2.0을 결합해 고품질 영상을 생성하는 새로운 멀티모달 AI 워크플로우를 소개한다.
Machine Delusions (@Machinedelusion)
0.1B 규모의 오디오 모델이 언급되며, 매우 작은 파라미터 규모에서도 인상적인 성능을 보이는 신형 AI 오디오 모델로 보인다. 경량화된 음성/오디오 모델의 가능성을 시사한다.
VoxCPM 2 공개: 중국 오픈소스 TTS 모델로 Qwen3-TTS와 견줄 품질을 단일 통합 모델로 제공. 30+ 언어 지원, 텍스트로 제어하는 무한한 음성 디자인, 48kHz 스튜디오급 오디오, diffusion-autoregressive 복제로 감정·음향 디테일을 강화. 데모·모델은 Hugging Face·ModelScope·GitHub에 공개.

🚀 VoxCPM 2 is live! 🎉 Another open-source AI #TTS model from China — and one that stands shoulder to shoulder with Qwen3-TTS, while bringing everything into a single unified model. After rapid iterations from V1 (zero-shot cloning) to V1.5 (long-form + fine-tuning), #VoxCPM has
Logan Kilpatrick (@OfficialLoganK)
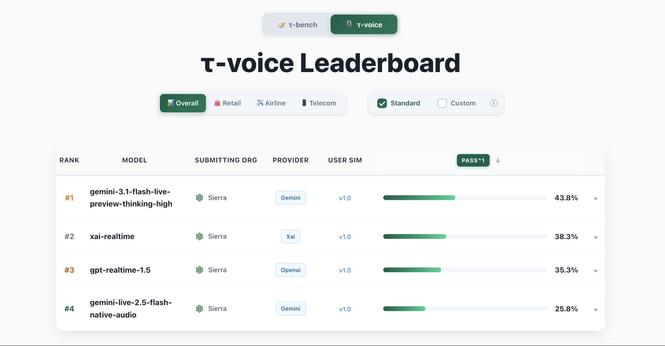
새 음성/오디오 모델이 이전 세대보다 훨씬 빨라졌으며, Tau Bench의 음성 리더보드에서 확인할 수 있다고 밝혔다. 오디오 모델 팀의 개선으로 생산성 높은 실시간 음성 AI 성능이 강화됐다.
Logan Kilpatrick (@OfficialLoganK)
최신 Live 모델이 Tau Voice Bench에서 1위를 기록했다. 음성 모델이 생산 환경에서 실제로 쓰일 만큼 유용해지고 있으며, 새로운 음성 AI 모델의 실사용 가능성과 성능 향상을 보여준다.
Google DeepMind (@GoogleDeepMind)
Lyria 3 Pro로 더 긴 음악 트랙을 만들 수 있게 됐다. 인트로, 벌스, 코러스, 브리지 같은 구조를 세밀하게 구성해 최대 3분 길이의 고음질 음악을 생성할 수 있으며, 음악 생성형 AI의 활용 범위를 넓히는 업데이트다.
Google DeepMind (@GoogleDeepMind)
Lyria 3라는 최신 생성 음악 모델이 공개되었습니다. 사진과 텍스트를 입력하면 보컬과 가사가 포함된 동적 트랙으로 변환할 수 있는 기능을 제공해 생성 음악과 오디오 제작 워크플로우를 크게 확장합니다.