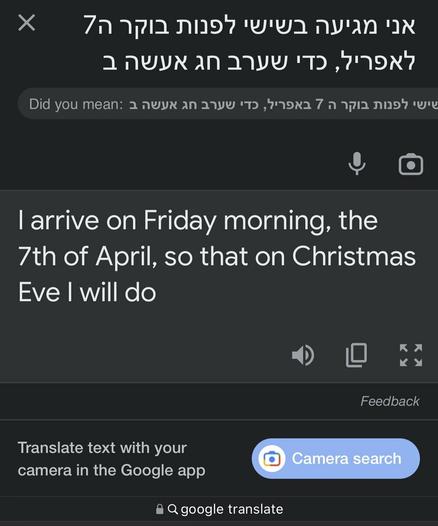
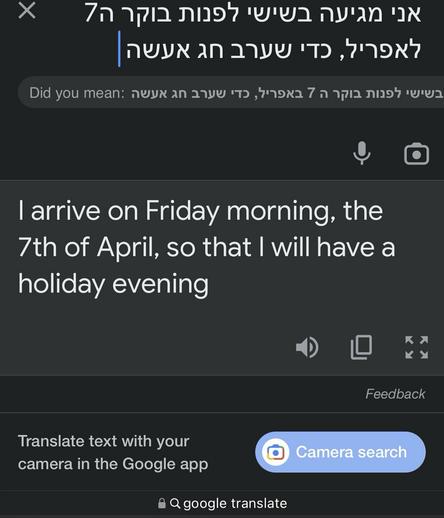
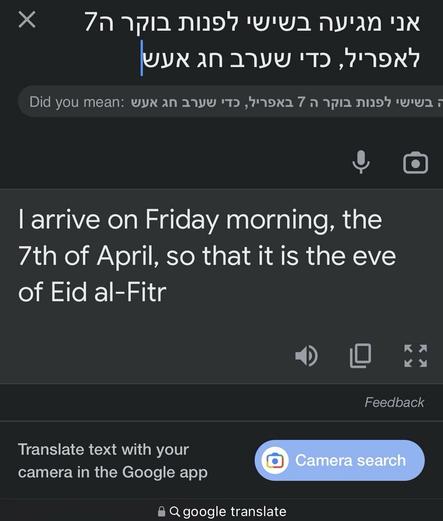
"... a software tool cannot be an author of a submission, in part because it cannot consent to terms of use and the right to distribute content."


| Website | https://yoavartzi.com/ |
| Cornell NLP | http://nlp.cornell.edu |
"... a software tool cannot be an author of a submission, in part because it cannot consent to terms of use and the right to distribute content."
🤘Right on
Several US-based newspapers have recently mentioned @[email protected] 's reply to a set of chatGPT lyrics purportedly "in his style". The reply speaks for itself. If you're into writing, LLM or ML-creativity, it's worth a read.
https://www.theredhandfiles.com/chat-gpt-what-do-you-think/
🐦🔗: https://twitter.com/adinamwilliams/status/1615454708507844624


Dear Mark, Since its launch in November last year many people, most buzzing with a kind of algorithmic awe, have sent me songs ‘in the...
This is probably the first paper to give ChatGPT coauthor status, and its contact details points to support@openai! Giving coauthorship to writing assistants is absurd and this practice has to stop. 🧶
Humans learn language by acting in the world. Can RL agents do the same? lilGym is a new benchmark 🏋️ for RL + natural language + visual reasoning
https://arxiv.org/abs/2211.01994
https://lil.nlp.cornell.edu/lilgym/
Chief RL trainer: @[email protected] , in collboration with @[email protected] and @[email protected]

We present lilGym, a new benchmark for language-conditioned reinforcement learning in visual environments. lilGym is based on 2,661 highly-compositional human-written natural language statements grounded in an interactive visual environment. We introduce a new approach for exact reward computation in every possible world state by annotating all statements with executable Python programs. Each statement is paired with multiple start states and reward functions to form thousands of distinct Markov Decision Processes of varying difficulty. We experiment with lilGym with different models and learning regimes. Our results and analysis show that while existing methods are able to achieve non-trivial performance, lilGym forms a challenging open problem. lilGym is available at https://lil.nlp.cornell.edu/lilgym/.
Users engaged with natural language systems can provide feedback in realtime, and this feedback is a super duper learning signal! So: deploy, train, repeat!
https://arxiv.org/abs/2212.09710
Last PhD paper w/@alsuhr/[email protected] ... 🧵
We propose and deploy an approach to continually train an instruction-following agent from feedback provided by users during collaborative interactions. During interaction, human users instruct an agent using natural language, and provide realtime binary feedback as they observe the agent following their instructions. We design a contextual bandit learning approach, converting user feedback to immediate reward. We evaluate through thousands of human-agent interactions, demonstrating 15.4% absolute improvement in instruction execution accuracy over time. We also show our approach is robust to several design variations, and that the feedback signal is roughly equivalent to the learning signal of supervised demonstration data.