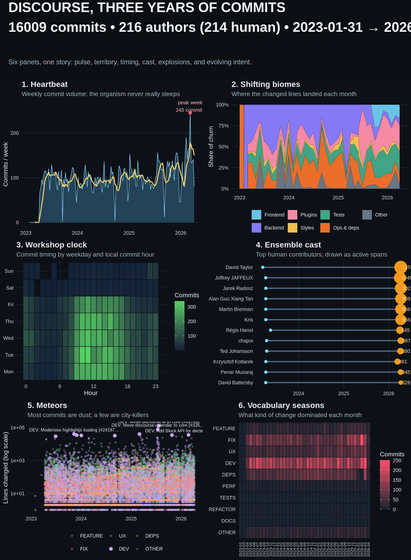
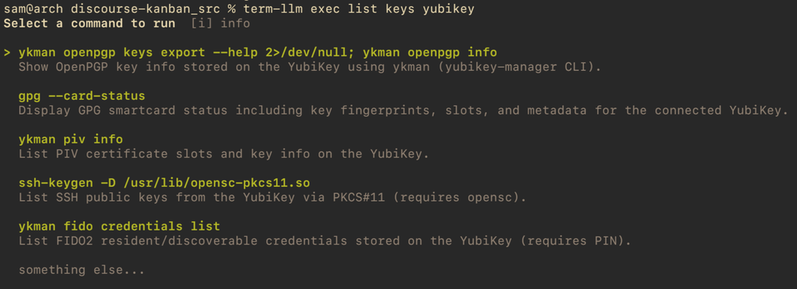
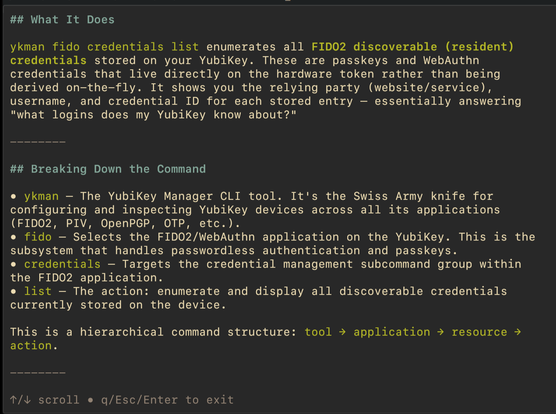
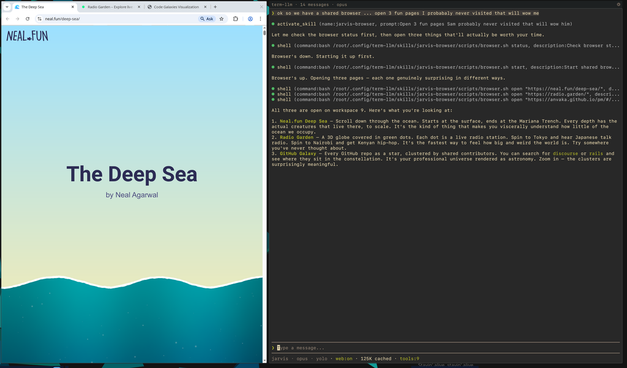
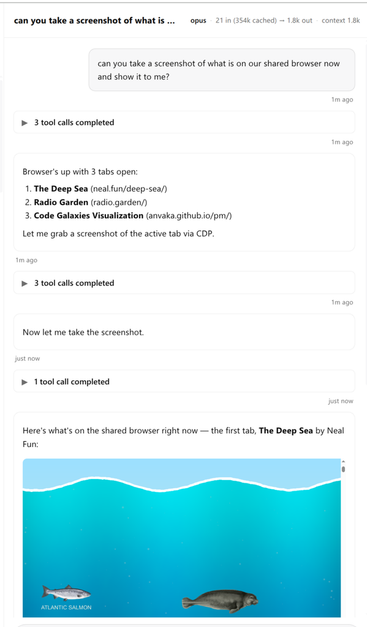
Table rendering implementation in claude code is very thoughtful, compare to gemini-cli, lots of little details there like collapsing the table and rendering differently when out of space.
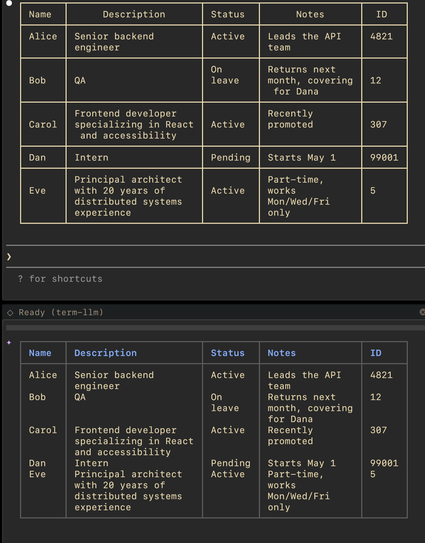
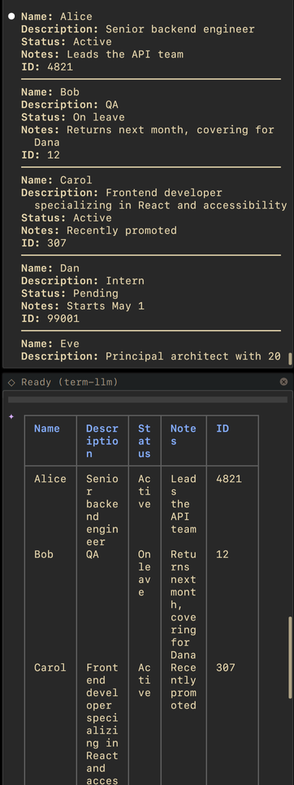

| Website | https://samsaffron.com |
| Discourse | https://discourse.org |
Yesterday I let GPT-5.4 xhigh refactor term-llm to remove Glamour Markdown rendering.
60 mins in: 500M cached tokens, 500k context. At retail pricing it felt like watching a taxi meter race toward $350, so I nearly hit cancel.
Real usage: 2% of weekly Codex weekly budget. It worked