Check out our new paper about predicting the auction price of contemporary art pieces! 🎨📈
https://www.nature.com/articles/s41598-024-60957-z
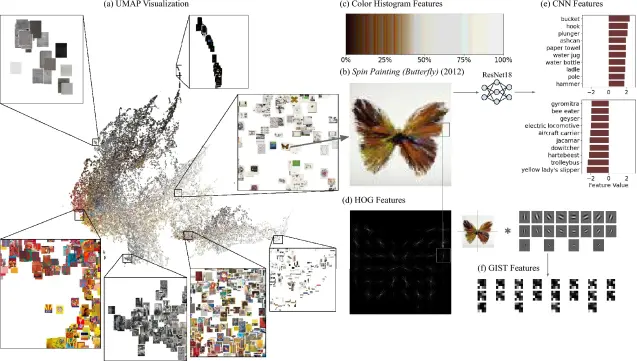
In this paper led by Kangsan Lee & Jaehyuk Park (w @samgoree and David Crandall), we examined a comprehensive dataset of art auctions of contemporary artists to understand what really determines the price of art. 🧵

Social signals predict contemporary art prices better than visual features, particularly in emerging markets - Scientific Reports
What determines the price of an artwork? This article leverages a comprehensive and novel dataset on art auctions of contemporary artists to examine the impact of social and visual features on the valuation of artworks across global markets. Our findings indicate that social signals allow us to predict the price of artwork exceptionally well, even approaching the professionals’ prediction accuracy, while the visual features play a marginal role. This pattern is especially pronounced in emerging markets, supporting the idea that social signals become more critical when it is more difficult to assess the quality. These results strongly support that the value of artwork is largely shaped by social factors, particularly in emerging markets where a stronger preference for “buying an artist” than “buying an artwork.” Additionally, our study shows that it is possible to boost experts’ performance, highlighting the potential benefits of human-machine models in uncertain or rapidly changing markets, where expert knowledge is limited.