This method has been entirely generated by AI. If you care about performances, you still have a job 🙂
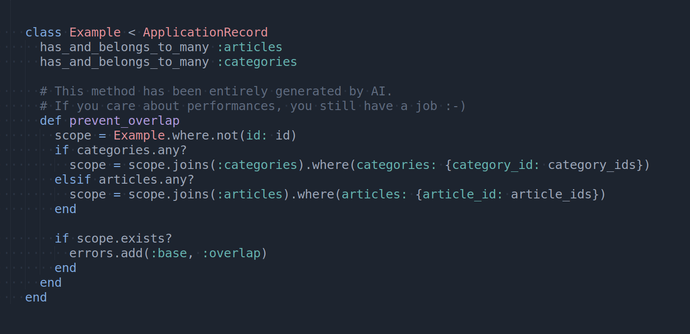

Read The Nice Manual!
In the happy world of #Ruby, we don’t #RTFM, we #RTNM
New documentation website for Ruby, Rails, and a bunch of selected gems:
rubyrubyrubyruby.dev
Short intro post:
www.rorvswild.com/blog/2025/re...
Contribute:
github.com/BaseSecrete/...
Wdyt?
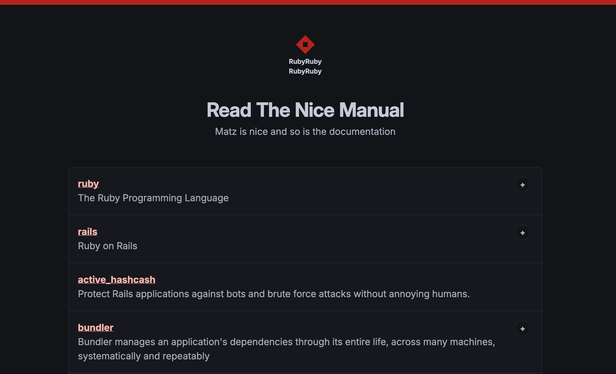
Here's my recipe to increase code coverage:
1. Set minimum code coverage with current value 📏
2. You're not allowed to decrease it ⛔️
3. Every week check the value and increase the minimum accordingly 🔄
4. Code coverage will slowly but magically increase ⬆️
🆕 ActiveAnalytics 0.4 – First-party, privacy-focused traffic analytics for Ruby on Rails applications.
Now with browsers stats!
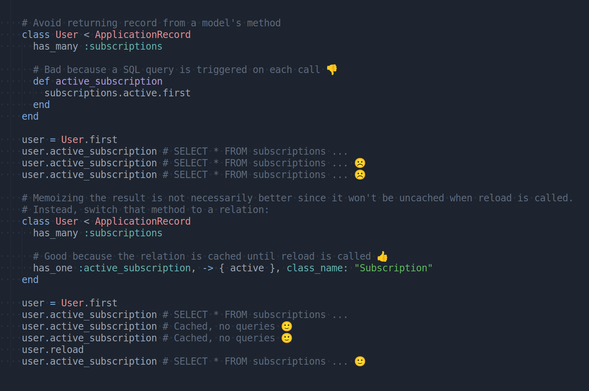
Avoid returning records from a model's method
Because a SQL query is triggered on each call. Memoizing the result is not necessarily better since it won't be uncached when reload is called. Instead, switch that method to a relation.
One step further
It works fine with a few thousand. But that would probably eat too much memory if you're loading a lot of ActiveRecord instances. The trick is to load IDs only if you do not need to access any attributes or methods.
Enqueuing a lot a jobs really fast
Enqueuing via ActiveJob::Base#perform_later triggers callbacks and generates one round-trip for each job. Bulk enqueuing skips callbacks and enqueues all jobs in one step.
For more details I encourage you to read this section of the README of redis-rb: https://github.com/redis/redis-rb?tab=readme-ov-file#pipelining
And of course the pipelining documentation of Redis: https://redis.io/docs/latest/develop/use/pipelining
Stop waiting for Redis responses with pipelining
Pipelining sends a bunch of commands without waiting for each individually. Instead of having N round-trips, there is only one, thus code is less idle. Of course, that's not possible when you need the result of the previous command for the next one.

