The same score can be derived for probabilistic circuits (PCs), or actually, for the sub-class of deterministic PCs! We use the score in a simple cutset learning algorithm and achieve excellent trade-offs between learning speed and test log-likelihoods.
Stay tuned for the paper, or catch up with us at #aistats23 in April! 😀
In short, a Bayesian structure score is simply the marginal likelihood of the structure G, integrating over model parameters θ: p(data | G) = ∫ p(data | G, θ) p(θ | G) dθ. Integrating over all parameterizations θ effectively protects against overfitting. A cool result is that, under certain assumptions, this score can be computed in closed form in Bayesian networks, see e.g. the classical paper by Heckerman, Geiger and Chickering, (1995).
I'm happy to share that our paper "Bayesian Structure Scores for Probabilistic Circuits" has been accepted at #aistats23! This is joint work with Yang Yang (MSc @mastodon.world, incoming PhD @leuvenai and Gennaro Gala.
The main contribution of the paper is to propose a new (actually old) way to learn the structure of #ProbabilisticCircuits. We take lessons from classical structure learning in Bayesian networks which optimizes some structure score, where a principled choice is a Bayesian score.
I will have an open #internship position @AaltoUniversity on #probabilistic #circuits.
The internship will be within Aalto's #AScI program, which is an excellent opportunity! See project 4116 in the announcement below.
🔗 https://www.aalto.fi/en/aalto-science-institute-asci/asci-international-summer-research-program-2023-project-list
#MachineLearning
AScI international summer research program: 2023 project list | Aalto University
Here are AScI's research projects for summer 2023.
We are happy if you drop by on Tuesday 29th Nov in New Orleans! Let's have a chat about this cool work!
Spotlight, Lightning Talks 1A-3, 12:00-12:15, presented by @chritoth
https://neurips.cc/virtual/2022/spotlight/65825
Poster session: 16:00-18:00.
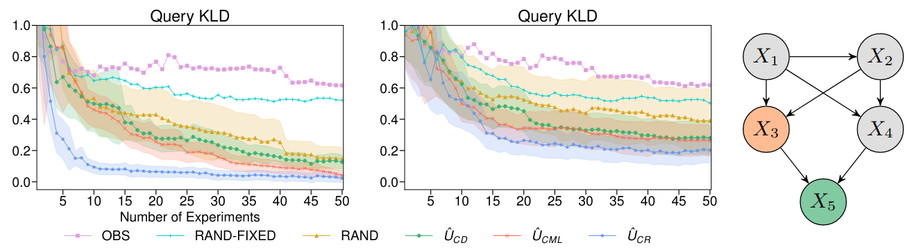
The implementation scales to several dozens of variables and indeed learns target causal queries faster than competing methods.
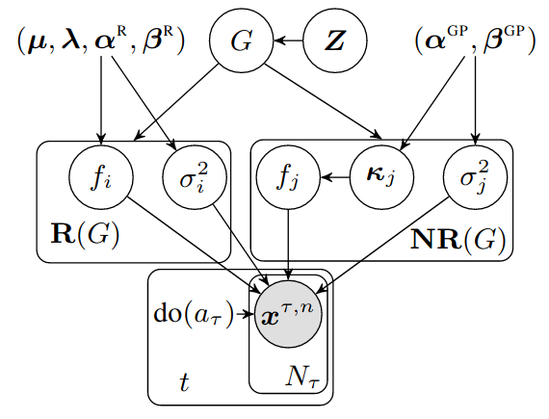
We have developed a tractable implementation for non-linear additive Gaussian noise models, using a DIBs prior over causal graphs and Gaussian processes for the causal mechanisms.
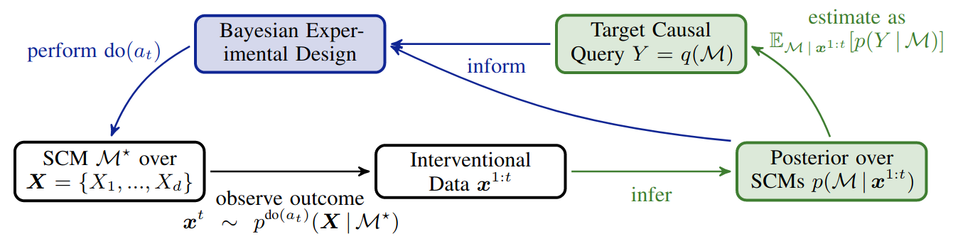
Advantage 4 is a combination of Advantage 2 and 3: we can get active about causal queries of interest, by maximizing Information Gain of the query posterior! Thus, even if we are still uncertain about the model, we might already be pretty certain about the target causal query!
Advantage 3. We can get active about learning the model, e.g. by maximizing Information Gain derived from our posterior. Roughly, this iteratively designs optimal interventional experiments, so that we learn as much as possible about the model.
Advantage 2. This uncertainty can be used for causal predictions using Bayes predictive distributions. Specifically, we define the "causal query function" q, which represents what we want to know from the model (the whole graph, particular edges, some causal effect, etc).