

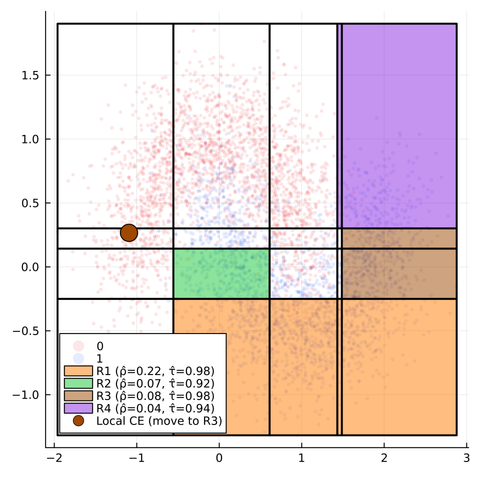
Counterfactual Explanations are typically local in nature: they explain how the features of a single sample or individual need to change to produce a different model prediction. This type of explanation is useful, especially when opaque models are deployed to make decisions that affect individuals, who have a right to an explanation (in the EU).
📜 Recent: https://arxiv.org/abs/2312.10648
🌐 Blog: https://www.paltmeyer.com/blog/
📦 Julia: https://www.paltmeyer.com/content/software.html
| Home | https://www.patalt.org/ |
| github | https://github.com/pat-alt |






