🔬 Our Testing Setup: We ran experiments using Pythia models (2.8B and 6.9B parameters) with training samples from The Pile dataset, comparing them to validation and test sets. This setup avoids data leakage to ensure a reliable evaluation of MIA.
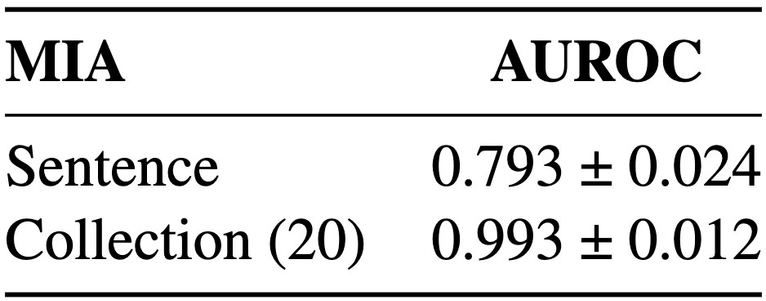
🔎 Better Results in Fine-Tuning: Fine-tuned models show even stronger MIA results. The table shows the performance at sentence level and for collections of 20 sentences, evaluated on Phi-2 fine-tuned for QA (https://huggingface.co/haritzpuerto/phi-2-dcot ).

haritzpuerto/phi-2-dcot · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
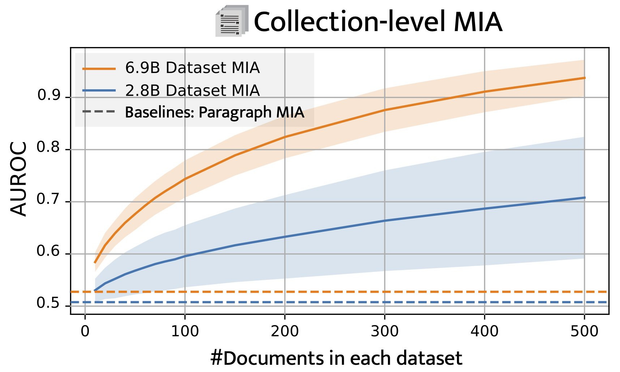
🚀 The Key? Number of tokens & Aggregation: MIA’s accuracy improves as we aggregate MIA scores across multiple paragraphs. Longer documents or larger document collections significantly boost MIA effectiveness.
🛠️ First Success on Pre-Trained LLMs: By adapting recent work on Dataset Inference, we successfully applied MIA on pre-trained LLMs. Check out our figure below: MIA achieves an AUROC of 0.75 on documents of up to 20k tokens!
🔍 New Benchmark, New Insights: We developed a new benchmark to assess MIA effectiveness across data scales, from single sentences to document collections. This lets us identify precisely when and how MIA succeeds on LLMs.
🚨📄 Exciting new research accepted at
#NAACL2025! Discover when and at what scale we can detect if specific data was used in training LLMs — a method known as Membership Inference (MIA)! Our findings open new doors for using MIA as potential legal evidence in AI. 🧵
https://arxiv.org/abs/2411.00154

Scaling Up Membership Inference: When and How Attacks Succeed on Large Language Models
Membership inference attacks (MIA) attempt to verify the membership of a given data sample in the training set for a model. MIA has become relevant in recent years, following the rapid development of large language models (LLM). Many are concerned about the usage of copyrighted materials for training them and call for methods for detecting such usage. However, recent research has largely concluded that current MIA methods do not work on LLMs. Even when they seem to work, it is usually because of the ill-designed experimental setup where other shortcut features enable "cheating." In this work, we argue that MIA still works on LLMs, but only when multiple documents are presented for testing. We construct new benchmarks that measure the MIA performances at a continuous scale of data samples, from sentences (n-grams) to a collection of documents (multiple chunks of tokens). To validate the efficacy of current MIA approaches at greater scales, we adapt a recent work on Dataset Inference (DI) for the task of binary membership detection that aggregates paragraph-level MIA features to enable MIA at document and collection of documents level. This baseline achieves the first successful MIA on pre-trained and fine-tuned LLMs.
📢 Parameter Lab will be at the #ACL2024 conference in Bangkok!
Come to see our two posters:
- TRAP 🪤 about black-box LLM fingerprinting: Tuesday 13 Aug 12:15-13:15
- Apricot 🍑 about black-box calibrated confidence score estimation: Tuesday 13 Aug 16:00-17:30
More information on the dedicated threads: https://sigmoid.social/@mgubri/112672246352542580 and https://x.com/dnnslmr/status/1767584342849556701

Attached: 1 image
🦹💥 How to detect if my LLM was stolen or leaked? 🤖💥
I am delighted to announce TRAP 🪤, our new #ACL2024 findings paper ☝️ We showcase how to use adversarial prompt as model fingerprint for LLM.
A thread 🧵
⬇️⬇️⬇️
Parameter Lab is looking for a *Research Intern* for roughly the period of October 2024 - February 2025. You’ll do research on trustworthy AI for LLMs or multi-modal foundational models. Your research work is expected to lead to a top-tier conference submission.
Prior intern projects:
- ProPILE (NeurIPS’23 spotlight): https://arxiv.org/abs/2307.01881
- TRAP (ACL’24 findings): https://arxiv.org/abs/2402.12991
- Apricot (ACL’24): https://arxiv.org/abs/2403.05973

ProPILE: Probing Privacy Leakage in Large Language Models
The rapid advancement and widespread use of large language models (LLMs) have raised significant concerns regarding the potential leakage of personally identifiable information (PII). These models are often trained on vast quantities of web-collected data, which may inadvertently include sensitive personal data. This paper presents ProPILE, a novel probing tool designed to empower data subjects, or the owners of the PII, with awareness of potential PII leakage in LLM-based services. ProPILE lets data subjects formulate prompts based on their own PII to evaluate the level of privacy intrusion in LLMs. We demonstrate its application on the OPT-1.3B model trained on the publicly available Pile dataset. We show how hypothetical data subjects may assess the likelihood of their PII being included in the Pile dataset being revealed. ProPILE can also be leveraged by LLM service providers to effectively evaluate their own levels of PII leakage with more powerful prompts specifically tuned for their in-house models. This tool represents a pioneering step towards empowering the data subjects for their awareness and control over their own data on the web.
🔍 In this #ResearchMonday's spotlight: a pivotal ICLR 2024 paper about fine-tuning LLM. It reveals that fine-tuning may only superficially align models, without deeply altering their pre-trained capabilities.
The authors also express enthusiasm for future research aimed at not just masking but potentially deleting or unlearning certain pre-trained capabilities, enhancing the safety and reliability of AI systems. 🛡️🤖
📜 https://arxiv.org/abs/2311.12786
🧵https://x.com/_robertkirk/status/1729531935637004717

Mechanistically analyzing the effects of fine-tuning on procedurally defined tasks
Fine-tuning large pre-trained models has become the de facto strategy for developing both task-specific and general-purpose machine learning systems, including developing models that are safe to deploy. Despite its clear importance, there has been minimal work that explains how fine-tuning alters the underlying capabilities learned by a model during pretraining: does fine-tuning yield entirely novel capabilities or does it just modulate existing ones? We address this question empirically in synthetic, controlled settings where we can use mechanistic interpretability tools (e.g., network pruning and probing) to understand how the model's underlying capabilities are changing. We perform an extensive analysis of the effects of fine-tuning in these settings, and show that: (i) fine-tuning rarely alters the underlying model capabilities; (ii) a minimal transformation, which we call a 'wrapper', is typically learned on top of the underlying model capabilities, creating the illusion that they have been modified; and (iii) further fine-tuning on a task where such hidden capabilities are relevant leads to sample-efficient 'revival' of the capability, i.e., the model begins reusing these capability after only a few gradient steps. This indicates that practitioners can unintentionally remove a model's safety wrapper merely by fine-tuning it on a, e.g., superficially unrelated, downstream task. We additionally perform analysis on language models trained on the TinyStories dataset to support our claims in a more realistic setup.
🔬 This week's
#ResearchMonday features a study titled "Scalable Extraction of Training Data from (Production) Language Models", revealing the brittleness of alignment in AI. The research shows that simply prompting a model like ChatGPT to repeatedly output a single word can lead to the unintended disclosure of its training data! ⛓️💥 This finding challenges the effectiveness of current alignment techniques, highlighting significant security vulnerabilities. 🛡️
📊 Soft prompt tuning uncovered a tighter worst-case PII leakage possibility. Soft prompt tuning shows a significant increase in the exact match rate and reconstruction likelihood. The found prompts can transfer from one model to another, as shown by a significantly higher likelihood obtained from transferred prompts compared to our handcrafted prompts.