FoldMason progressively aligns thousands of protein structures in seconds, enabling remote MSA for distant phylogeny. Highlights: structural flexible MSA, LDDT conservation score, friendly webserver.
💾
https://github.com/steineggerlab/foldmason 🌐
https://search.foldseek.com/foldmason 📄
https://www.biorxiv.org/content/10.1101/2024.08.01.606130v1
GitHub - steineggerlab/foldmason: Multiple Protein Structure Alignment at Scale with FoldMason
Multiple Protein Structure Alignment at Scale with FoldMason - steineggerlab/foldmason
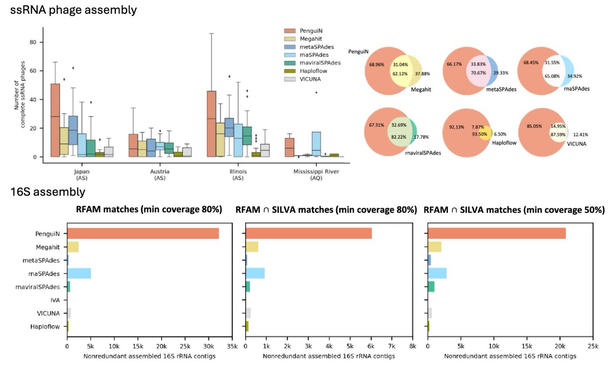
Penguin is our new assembler that reconstructs manyfold more accurate strain-level viral genomes and 16S rRNAs from metagenomes through a novel greedy AA/DNA-hybrid bayesian overlap extension strategy. Work by Annika Jochheim et al.
📄
https://www.biorxiv.org/content/10.1101/2024.03.29.587318v1💾
https://github.com/soedinglab/plassWe found similarities between un- and annotated domains (Frag1, Anthrax_toxA, and Gasdermin) with cluster-based domain decomposition. We found e.g. novel gasdermin domains in unannotated clusters similar to bacterial ones. Our study shows the potential for unknown functions. 7/n
We found clusters containing human and bacterial structures. Human histones (previously identified by Vikram Alva et al.) and innate immunity genes (BPI and AIM2) have cross-kingdom structurally similarity to bacteria, showing possible sharing of immunity-related proteins. 6/n
By mapping the clusters to the tree of life, we found that the majority of non-singleton clusters are likely to be ancient in origin, with 23%, 16.1%, and 13.5% conserved at the Cellular organism, Bacterial, and Eukarya levels, respectively. 5/n
We investigated our “dark clusters” with DeepFRI, predicted 5324 functions and identified 1770 pockets within 1707 well-predicted structures using AutoSite. We found evidence that these may contain a large number of membrane-bound proteins, inc. putative transporters. 4/n
Out of the 2.3M clusters we identified, over 700k clusters that do not have any annotation in Pfam/TigerFam or align to PDB using Foldseek. While these clusters tend overall to have fewer members than annotated ones, these still contain hundreds to thousands of structures. 3/n
We extended the MMseqs2/Linclust clustering to structures and implemented it in Foldseek. To cluster 214M structures, we first cluster at 50% sequence identity with MMseqs2 followed by Foldseek structural clustering. Resulting in 2.3M clusters with ≥2 structures. 2/n
Our work on clustering the 214M AlphaFold protein structure was published in Nature. We identified 2.3M clusters using our fast structure cluster algorithm and analysed its annotations, evolution and novel domains. Amazing collaboration with Pedro Beltrao. 1/n
📄
https://www.nature.com/articles/s41586-023-06510-w💾
https://cluster.foldseek.com
Clustering-predicted structures at the scale of the known protein universe - Nature
The novel Foldseek clustering algorithm defines 2.30 million clusters of AlphaFold structures, identifying remote structural similarity of human immune-related proteins in prokaryotic species.
Foldseek Release 8: supporting searches against clustered databases (with prebuilt DBs for AFDB50 and PDB100) and protein-complexes. HTML output was improved by
Cameron Gilchrist. In the webserver, you can download and (re)upload results.
💾
https://github.com/steineggerlab/foldseek/releases/tag/8-ef4e960 or bioconda 🐍

Release 8-ef4e960 · steineggerlab/foldseek
At a glance: Added support for clustered, protein-complex searches as well as improved HTML output.
Features
Implement easy-complex-search to find similar complexes structures in a database
Implem...