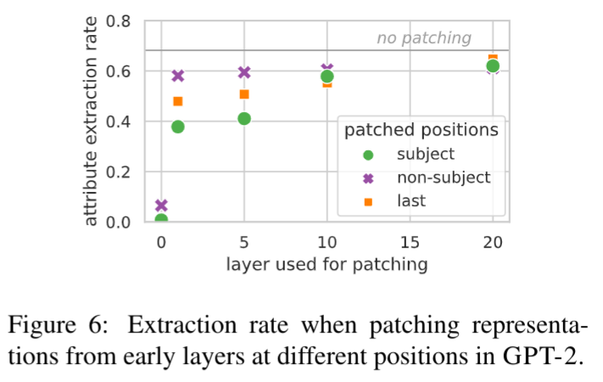
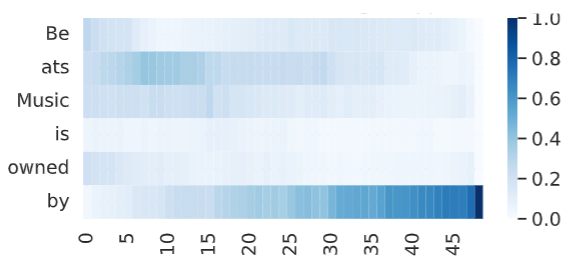
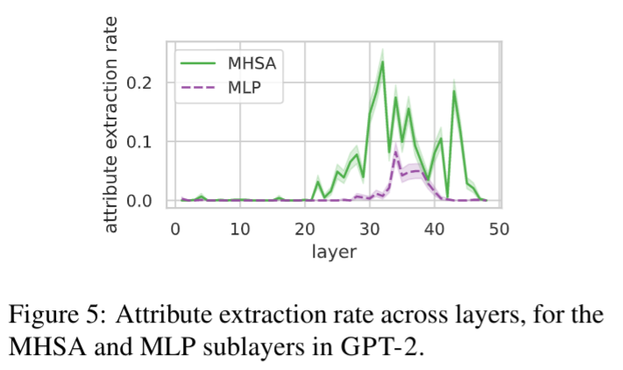
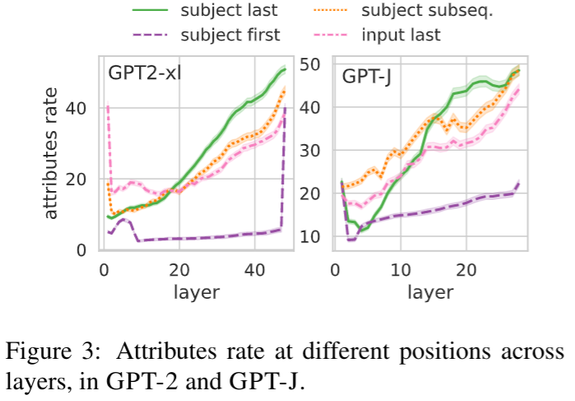
Thread: Excited to announce the v1.0 release of the Learning Interpretability Tool (🔥LIT), an interactive platform to debug, validate, and understand ML model behavior. This release brings exciting new features — including layouts, demos, and metrics — and a simplified Python API. https://pair-code.github.io/lit
(1/5)