Welcome to the Nordics, - Finland in this case - where you can leave your phone unattended while charging.


Heavily nerd adjacent. Dilettante neurodiverse. Cis with 1 Y chromosome.
Perpetually existential and filled with incredulous awe for the cosmos.
Nurturing a budding relationship with that for which we have no name.
Pro Gaia, pro nuclear energy.
Today is a good day, for today I bent #plotly to my #cyberpunk will!
Not shown here: The retro pixelated C64 like font

Realised that no. rows might be more relevant x-axis than number of times data was added (as one add could be 1 row or tens of thousands)
Settled on a relational db now, of course. Refining the python sqlite db manager module before testing DuckDB. I have expectations!

Moving from CSV files to something more... just better.
Parquet, #Sqlite or DuckDB are on the table.
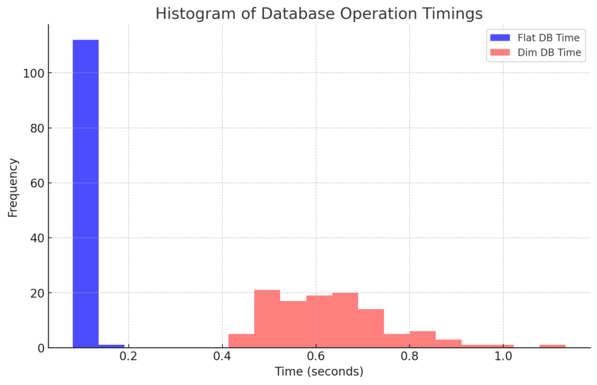
Doing some benchmarking, just for Sqlite for now, comparing one flat table vs. a relational one.
Inserts are slower, but the size is kept manageable with relations.
Nothing surprising, but I like seeing the exact differences for my particular use case.

New hobby enjoyment!
Distance is *very* short; just practicing form and getting to know my first ever bow. It's purple! (Yea, I'm new enough to care about that 😄)
DIY impromptu improvised cardboard target.

And I did that, which was trivial, and did not feel like real programming at all.
Also, fiddling to get my chosen ORM to accept a slice where SQLite will accept no such thing, but a string, also feels far from "real" programming.
But I knew this.
If I had *really* wanted *real* programming I would have had *real* spare time and no practical use cases, only creative ones.



