Style (and mindset) tips for less experienced developers working with AI https://honnibal.dev/blog/llm-style-tips
| Blog | https://honnibal.dev |
| Explosion | https://explosion.ai |
| https://twitter.com/honnibal | |
| https://www.linkedin.com/in/honnibal/ |

| Blog | https://honnibal.dev |
| Explosion | https://explosion.ai |
| https://twitter.com/honnibal | |
| https://www.linkedin.com/in/honnibal/ |
Just published part 3 of my blog post series on making beautiful slides for your talks 🎨✨
This one is about presenting technical content and making dry and abstract topics more interesting. Featuring many examples, including talks by Vitaly Meursault and @sofie!
https://ines.io/blog/beautiful-slides-talks-part-3-technical-content/

spaCy and Prodigy started as indie projects, but in 2021 we decided to raise capital and have a larger team. We couldn’t make that configuration work, so we’re back to how we were before. I’ll be spending most of my time hands-on with spaCy again, and we have a lot of updates and improvements planned for Prodigy.
I hate how vaguely these things are usually discussed, so I also wrote a long post about it all: https://honnibal.dev/blog/back-to-our-roots
Company update: We're going back to our roots!
We're back to running Explosion as a smaller, independent-minded and self-sufficient company. spaCy and Prodigy will stay stable and sustainable and we'll keep updating our stack with the latest technologies, without changing its core identity or purpose 💙
We are really excited to share that we have just released the alpha version of Prodigy v1.12! This includes LLM-assisted workflows for data annotation and prompt engineering as well as extended, fully customizable support for multi-annotator workflows.


Hey everyone! We are really excited to share that we have just released the alpha version of Prodigy v1.12! (v1.12a1). This release is available for download for all v.1.11.x license holders and includes: New recipes for LLM-assisted annotations and prompt engineering: the LLM assisted workflows we have announced a while ago are now fully integrated with Prodigy and available out of the box. For v1.12a1 you'd still be restricted to OpenAI API to use them, but by v1.12a2 we definitely want to...
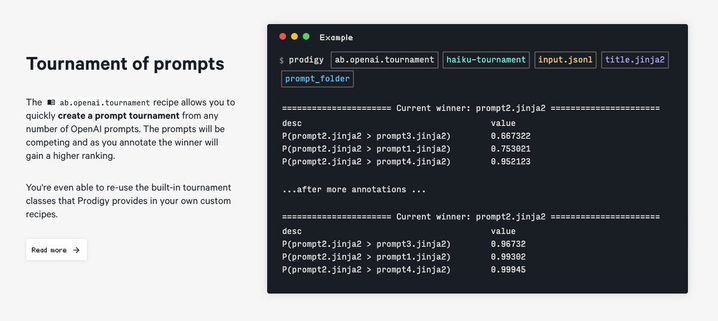
We present a brand new workflow for prompt engineering that allows you to compare the quality of several prompts in a tournament. The algorithm uses the Glico ranking system [https://en.wikipedia.org/wiki/Glicko_rating_system] to select the best prompt.
https://future--prodi-gy.netlify.app/docs/large-language-models#tournaments
Here are the slides for my #PyDataLondon keynote on LLMs from prototype to production ✨
Including:
◾ visions for NLP in the age of LLMS
◾ a case for LLM pragmatism
◾ solutions for structured data
◾ spaCy LLM + https://prodi.gy
https://speakerdeck.com/inesmontani/large-language-models-from-prototype-to-production

What will production NLP look like, once the dust settles around LLMs? One view is basically “prompts are all you need”. I disagree. I wrote a bit about this when we released #spaCy LLM last week, but the topic deserves its own post, so here it is.

LLMs are not a direct solution to most of the NLP use-cases companies have been working on. They are extremely useful, but if you want to deliver reliable software you can improve over time, you can't just write a prompt and call it a day. Once you're past prototyping and want to deliver the best system you can, supervised learning will often give you better efficiency, accuracy and reliability.


Machine learning is basically programming by example: instead of specifying a system's behaviour with code, you (imperfectly) specify the desired behaviour with training data.
Well, zero-shot learning is like that, but without the training data. That does have some advantages — you don't have to tell it much about what you want it to do. But it's also pretty limiting. You can't tell it much about what you want it to do.


