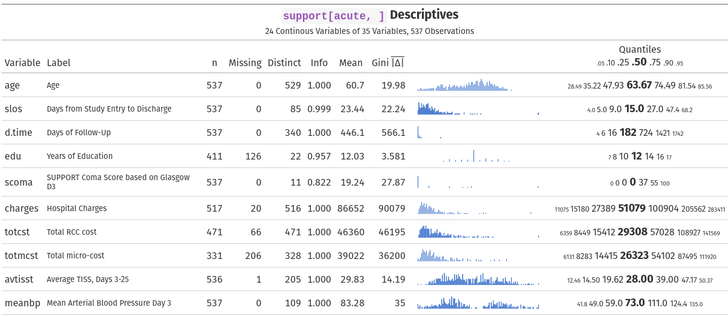
The #rstats Hmisc package has another major update. One of the biggest changes is new output options for describe() including interactive sparklines for spike histograms. http://hbiostat.org/R/Hmisc
@VUMCbiostat @datavisFriendly @datascience
@VUMCbiostat @datavisFriendly @datascience