RT @cwolferesearch
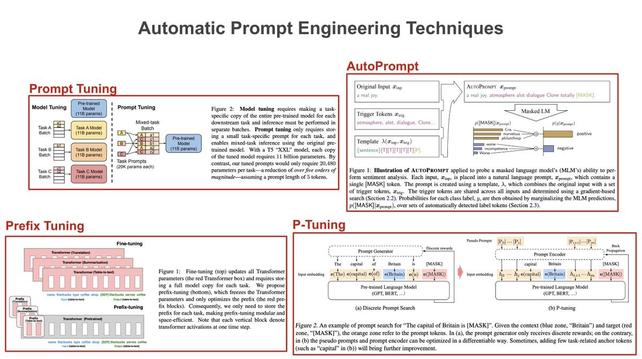
Prompt engineering for language models usually involves tweaking the wording or structure of a prompt. But, recent research has explored automated prompt engineering via continuous updates (e.g., via SGD) to a prompt’s embedding. Here’s how these techniques work… 🧵 [1/8]
Prompt engineering for language models usually involves tweaking the wording or structure of a prompt. But, recent research has explored automated prompt engineering via continuous updates (e.g., via SGD) to a prompt’s embedding. Here’s how these techniques work… 🧵 [1/8]