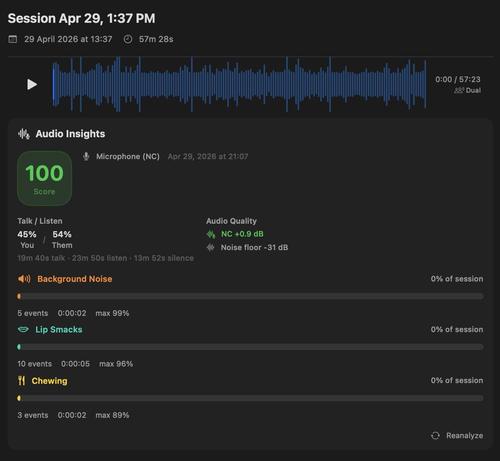
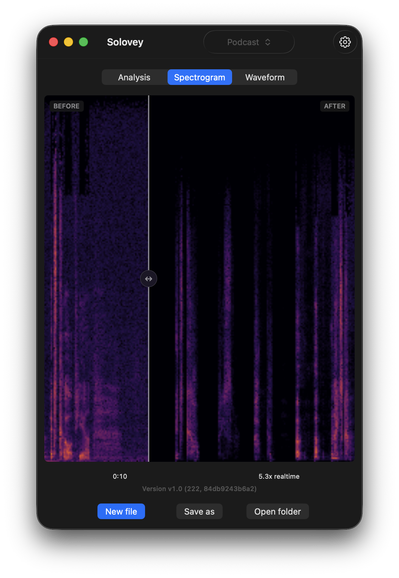
Monday I'm sending out invites to https://tish.bshk.app/?utm_source=x&utm_medium=organic_social&utm_campaign=tish_alpha_2026_05_31&utm_content=en_post
If you're interested, you can sign up as an alpha tester by sending me your email, or subscribe for updates via the link.
Alpha testers get the PRO version free during the alpha test and a 50% discount once it ends.