
Today marks 50 years since John Chambers and Rick Becker presented a new project to colleagues at Bell Labs - an interactive environment that became the S language.
For more details, see the #RStats blog entry "S at 50":

| Website | https://andreanini.com/ |
| Github | https://github.com/andreanini |
| Google Scholar | https://scholar.google.com/citations?user=NP1NQxEAAAAJ&hl=en |
| Bluesky | https://bsky.app/profile/andreanini.com |
Today marks 50 years since John Chambers and Rick Becker presented a new project to colleagues at Bell Labs - an interactive environment that became the S language.
For more details, see the #RStats blog entry "S at 50":
Job offer: Post-doctoral researcher (m/f/x) in emoji semantics 😊
"Our research primarily concentrates on the semantics of face emojis, and builds on the hypothesis that face emojis have partly conventionalized (symbolic) meaning, but also incorporate iconic meaning due to their resemblance to human faces, which they are meant to depict. We aim to delineate the formal semantic denotation of face emojis, and whether it can be decomposed into smaller meaning components. Second, we aim to empirically establish the semantic type of expressive face emojis, i.e., whether or not they serve as functions, taking a propositional argument that they comment on."
location: #Bochum, Germany
https://linguistlist.org/issues/37/1362/
#PostDoc #academia #AcademiaJobs #ResearchJobs #JobOffers #linguistics
Announcing Zotero 9, with Read Aloud, a Recently Read collection, direct annotation citing, and more
The Book of Abstracts for DH2025 is (finally!) online! https://zenodo.org/records/19494802
Huge thanks to the Digital Humanities 2025 team, Walter Scholger and colleagues #DH2025 #DigitalHumanities
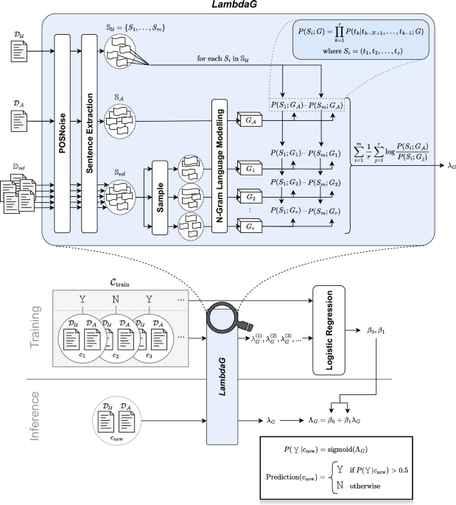
Authorship Verification (AV) is a key area of research in digital text forensics, which addresses the fundamental question of whether two texts were written by the same person. Numerous computational approaches have been proposed over the last two decades in an attempt to address this challenge. However, existing AV methods often suffer from high complexity, low explainability, and especially from a lack of clear scientific justification. We propose a simpler method based on modeling the grammar of an author following Cognitive Linguistics principles. These models are used to calculate λG (LambdaG): the ratio of the likelihoods of a document given the candidate’s grammar versus given a reference population’s grammar. Our empirical evaluation, conducted on 12 datasets and compared against seven baseline methods, demonstrates that LambdaG achieves superior performance, including against several neural network-based AV methods. LambdaG is also robust to small variations in the composition of the reference population and provides interpretable visualizations, enhancing its explainability. We argue that its effectiveness is due to the method’s compatibility with Cognitive Linguistics theories, predicting that a person’s grammar is a behavioral biometric.
Well-known #forensic #linguistics cases involved impersonation, e.g. murderer pretending to be the victim in text messages. In a new preprint with Baoyi Zeng we show that #LLMs can't fool authorship verification methods via prompting alone. Paper on arXiv: https://arxiv.org/abs/2603.29454

Authorship verification (AV), the task of determining whether a questioned text was written by a specific individual, is a critical part of forensic linguistics. While manual authorial impersonation by perpetrators has long been a recognized threat in historical forensic cases, recent advances in large language models (LLMs) raise new challenges, as adversaries may exploit these tools to impersonate another's writing. This study investigates whether prompted LLMs can generate convincing authorial impersonations and whether such outputs can evade existing forensic AV systems. Using GPT-4o as the adversary model, we generated impersonation texts under four prompting conditions across three genres: emails, text messages, and social media posts. We then evaluated these outputs against both non-neural AV methods (n-gram tracing, Ranking-Based Impostors Method, LambdaG) and neural approaches (AdHominem, LUAR, STAR) within a likelihood-ratio framework. Results show that LLM-generated texts failed to sufficiently replicate authorial individuality to bypass established AV systems. We also observed that some methods achieved even higher accuracy when rejecting impersonation texts compared to genuine negative samples. Overall, these findings indicate that, despite the accessibility of LLMs, current AV systems remain robust against entry-level impersonation attempts across multiple genres. Furthermore, we demonstrate that this counter-intuitive resilience stems, at least in part, from the higher lexical diversity and entropy inherent in LLM-generated texts.
New event! Our first German introductory course to forensic linguistics!
Werde Teil des 1. Einführungskurses Grundlagen der Forensischen #Linguistik am 28. + 29. September 2026 in Düsseldorf!
Bewirb dich bis zum 21. Mai 2026!

My #RStats package for forensic authorship analysis, 'idiolect', now has an associated paper published in the Journal of Open Source Software: https://doi.org/10.21105/joss.07575. New release of idiolect, 1.2.0, also available from #CRAN.
#forensic #linguistics
http://andreanini.com/2026/03/15/idiolect-an-r-package-for-forensic-authorship-analysis/

