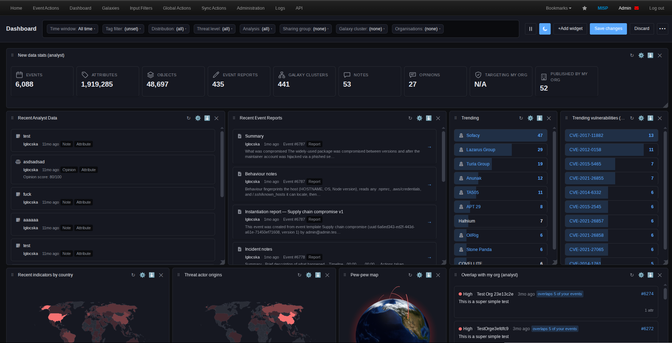
Checkpoint - User Authentication Bypass in VPN Remote Access and Mobile Access
Enjoy when humans are using machines in unexpected ways. I break stuff and I do stuff.
The other side is at @a (photography, art and free software at large)
#infosec #opensource #threatintelligence #fedi22 #threatintel #searchable
| Website | https://www.foo.be |
| GitHub | https://github.com/adulau |
| Matrix | @adulau:matrix.circl.lu |
| ORCID | https://orcid.org/0000-0002-5437-4652 |
| PGP FP | 6BB5 6353 1D99 F112 4C00 8C4F 815D 4786 1ECB 73D5 |
| Other Mastodon | https://paperbay.org/@a |