
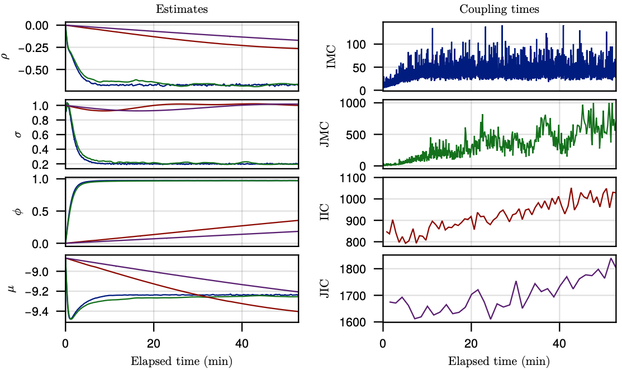
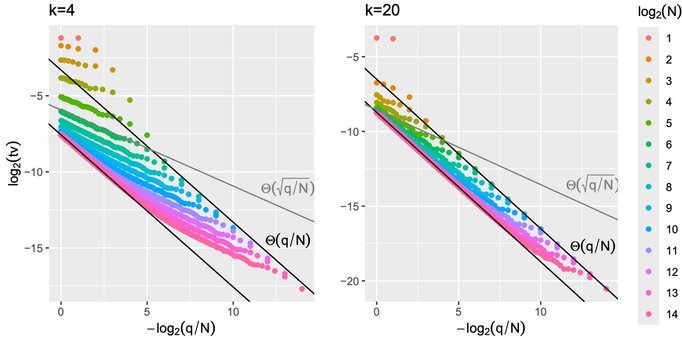
Substantial new content:
• New example which shows that the O(log N) rate in total variation forgetting is optimal, where N is the number of particles
• Propagation-of-chaos bounds (total variation distance between the law of q particles out of N and the i.i.d. draw from the ideal filter) which vanish if q = o(N)
• Method for handling out-of-sequence measurements

On the Forgetting of Particle Filters
We study the forgetting properties of the particle filter when its state - the collection of particles - is regarded as a Markov chain. Under a strong mixing assumption on the particle filter's underlying Feynman-Kac model, we find that the particle filter is exponentially mixing, and forgets its initial state in $O(\log N )$ 'time', where $N$ is the number of particles and time refers to the number of particle filter algorithm steps, each comprising a selection (or resampling) and mutation (or prediction) operation. We present an example which shows that this rate is optimal. In contrast to our result, available results to-date are extremely conservative, suggesting $O(α^N)$ time steps are needed, for some $α>1$, for the particle filter to forget its initialisation. We also study the conditional particle filter (CPF) and extend our forgetting result to this context. We establish a similar conclusion, namely, CPF is exponentially mixing and forgets its initial state in $O(\log N )$ time. To support this analysis, we establish new time-uniform $L^p$ error estimates for CPF, which can be of independent interest. We also establish new propagation of chaos type results using our proof techniques, discuss implications to couplings of particle filters and an application to processing out-of-sequence measurements.

