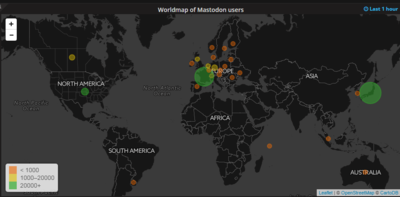
(「マストドン」は、米国とEUの間で個人情報データ保存場所(いわゆるセーフハーバー問題)に関する議論がなされている昨今、脱中央集権(具体的には米国大手IT企業)の概念を持つEU圏の若者によって開発されたわけで、このプラットフォームの真の意味は、インスタンス所在地のジオグラフ(※)を見れば「人的コミュニケーションとしての"ザ・インターネット"」の実質的な再構築であることにピンと来る人はピンと来るかと思うんだけど、果たしてその視点を持って現象を捉えてる日本人がどれだけいるかが、日本語圏ユーザーの観察の中で自分が気になっている点の一つです。)
【※】
#Mastodon🐘 Network Monitoring
#マストドン🐘 インスタンス統計サイト
https://mnm.eliotberriot.com https://mastodon.social/media/XmSTGuVSpq6TonSxr1o
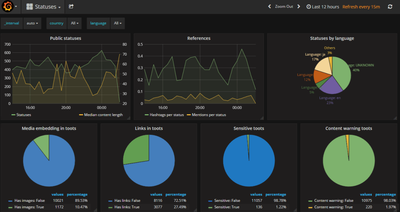
【※】
#Mastodon🐘 Network Monitoring
#マストドン🐘 インスタンス統計サイト
https://mnm.eliotberriot.com https://mastodon.social/media/XmSTGuVSpq6TonSxr1o