RE: https://hachyderm.io/@mnl/116715814203059670
one day someone skeptical of #llm #llms will take me up on this. my timeline still feels like i'm living in an alternate universe.
RE: https://hachyderm.io/@mnl/116715814203059670
one day someone skeptical of #llm #llms will take me up on this. my timeline still feels like i'm living in an alternate universe.
@adr yeah, even small models are wild, i can definitely do gpt-4 era work on my i7 laptop. there's still a gap that has huge impact in practical use between glm-5.1 (haven't tried out the newest batch with M3 and co) and gpt-5.5, but darn it's close (the practical gap being that I can let gpt-5.5 rip and go for a walk and at worst expect things to be unfinished, vs glm-5.1 getting lost in the weeds and nuking shit when it does)
labor implications for sure, there's no value in handcrafted code. and if the machine _actually_ does a better job for most programming tasks that engineers get paid for, refusing to use that technology just makes you ... a bad engineer. Which is ofc genuinely scary, but IMO it just means we need to seriously sit down and discover what software engineering looks like now that computers can code/architect/maintain.
@mnl @adr the gap is incredible and does a huge disservice to debates, especially with comrades here on Masto...
I just tried Claude Fable in Claude Code (the little I could on a company subscription) and had involuntary giggles of delight after throwing a lazily ambiguous and very ambitious task at it and watching it coming up with plans that took what I asked and extrapolated my intentions into some really nice solutions.
Meanwhile, I also recently managed to talk my boss into grabbing a refurbished 128GB M3 Max MBP for £3K and it runs MiniMax 2.7 at Q3_K_S with RAM left for actual computer usage and that model shows up in a tough agentic coding benchmark: https://cognition.ai/blog/frontier-code
It runs at a pretty incredible 25 tokens / sec output (only 11B active parameters) and can do so much of the stuff only the biggest frontier models could not even a year ago...
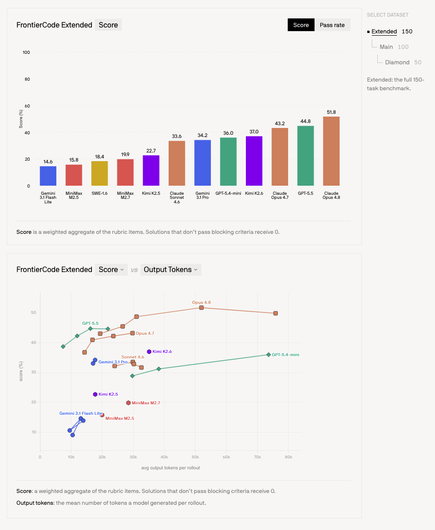
@dain @adr it's really impressive, and I think the real bubble burst will be when a good enough for all intents and purposes model can run on a local notebook, or a mom and pop inference hoster (of which there are already so many!). I already can't really care about opus 4.8, fable, and certainly wouldn't if i had to pay anything close to api costs on them.
and in the meantime opensource communities (i care very much about opensource and people being able to use their computers for their own needs) are putting up walls as a way to... cement the status quo??
@mnl @adr I'm totally with you, would never (even ask my company to) pay for the full API token costs, it's more just amusing myself with how much I can push my ambitions on a £90 subscription.
A 3 grand laptop is of course expensive, but it's also not completely outrageous as a business expense you can write off and Minimax is already there even to do most agentic work a less techy person or business would need.
Yeah, the situation in open source is a bit sad, but in a way I think it's also good that some projects stay "pure" and we finally need to have very explicit debates about governance.