What's your opinion on using the default unix "file" tool vs DROID to roughly-and-quicky-identify mixed data sets?
🙋♀️ ❓
What's your opinion on using the default unix "file" tool vs DROID to roughly-and-quicky-identify mixed data sets?
🙋♀️ ❓
@p3ter I like it because it's a bit easier to use, or I compromise and use Siegfried because of Siegfried's structured output.
If you're not going to persist the identifiers, or need to conform to a digital preservation standard and use the PUID then file good, quick and easy.
RE: processing you can maybe check out https://kellyjonbrazil.github.io/jc/ which allows you to pip file output to json, e.g. file * | jc --file
Which helps make it a bit easier to process by machine.
@beet_keeper to clarify what you mean:
"you like *it*" means droid or file?
(Haven't used Siegfried yet. Will try. This one, right? https://github.com/richardlehane/siegfried)
I've had quite some cases with AV files where file gets it, but DROID doesn't...
@beet_keeper ...oh, and since recently, I'm using my "holodex" #xattr key/value data for such things:
If you look at the screenshot, you'll see:
exiftool + mediainfo + other extracted data in one place.
I can query over this.
Brilliant. ❤️ ⭐️
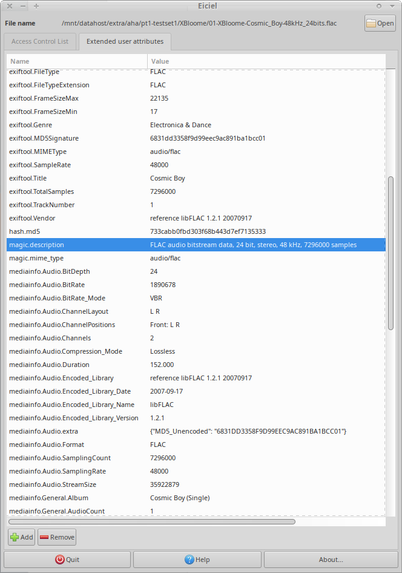
@beet_keeper But to be clear: The filetype identification parts still rely on the tool-internal capabilities/patterns, which are then stored as-is in xattrs.
Do DROID or Siegfried distinguish between AV files with same container, but different stream encodings?