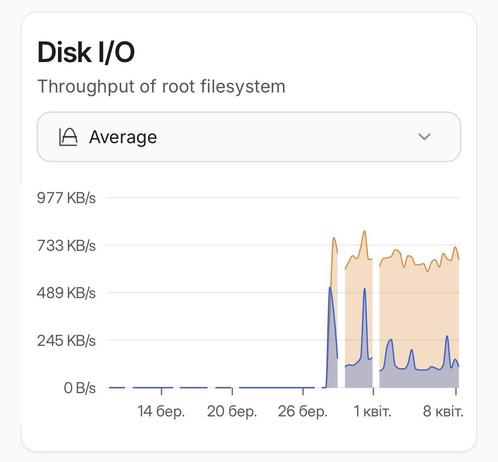
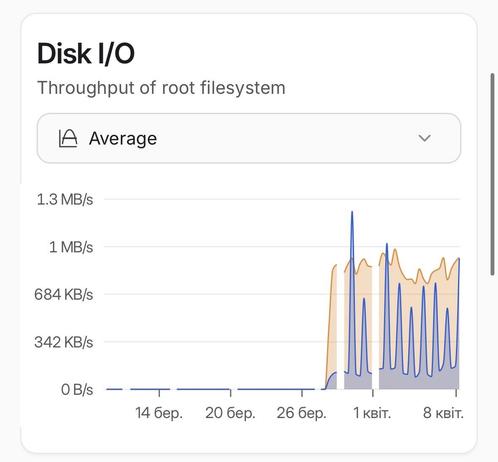
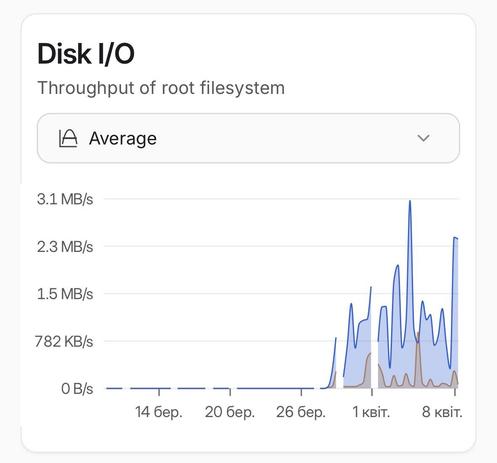
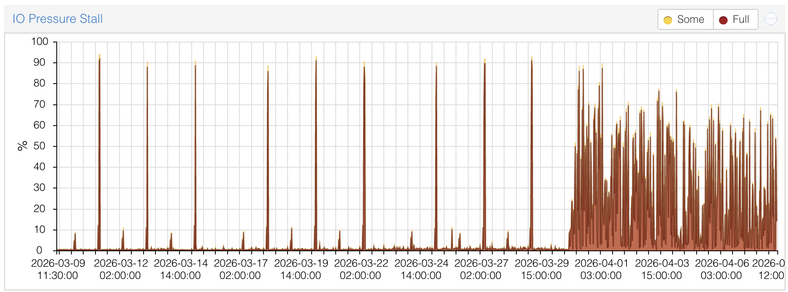
This is a disk I/O report for the last 30 days of every #Proxmox node of a cluster. Something happened around March 28 that caused high disk usage, and I can’t figure out what. The replication tasks are failing randomly, and actually, any disk operations are slowed down. Also, there are no significant changes in CPU, RAM, or network usage.
I was hoping to find which LXCs are causing this, but they all have similar disk IO graphs.
Well, shit.
#homelab #ProxmoxCluster #HighDiskUsage #zfs #mystery
I was hoping to find which LXCs are causing this, but they all have similar disk IO graphs.
Well, shit.
#homelab #ProxmoxCluster #HighDiskUsage #zfs #mystery