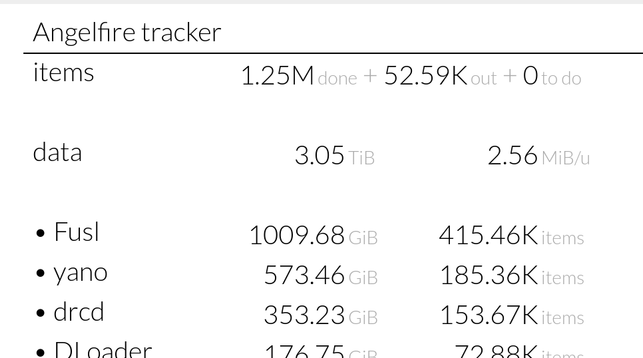
VERY urgent that you guys backup and archive AngelFire sites, we probably have like 2 weeks.

@ocean Archive Team are on it, it seems: https://wiki.archiveteam.org/index.php/Angelfire . Probably best to go check on the status over there on their IRC. It's very easy to contribute to Archive Team rescue ops, they have a VM image for volunteers to run that joins their swarm and contributes some bandwidth to the effort.
EDIT: looks like maybe not actively crawling it right now, but if Angelfire's death is making you have activist feelings about preserving the old web, ArchiveTeam is the crew for you! They have a swarm of crawlers that can be retasked to new things, they may just need someone who cares to write the necessary code to spin up the crawl. Not sure if you can go from zero to useful in the timeframe Angelfire needs, but if you want to be a preservation activist in general, you'll probably have more impact with them than alone.