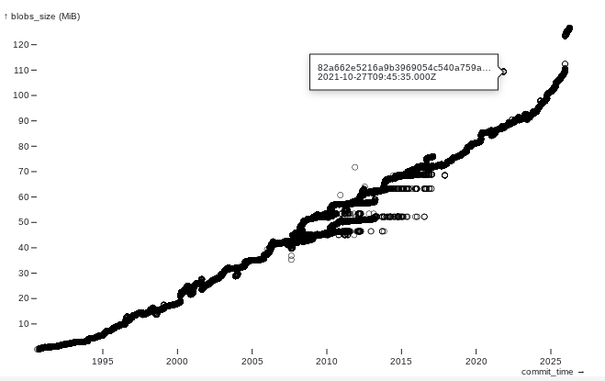
We have a git repo that uses git-lfs. We had a scare where we realized the repo was much bigger than the files in it and concluded something large was not in lfs. In fact the problem was the lfs cache was big.
For a minute there, I was considering writing a script that checked every file and its lfs status, and gave you the largest file that is not in lfs and maybe the file extension that contributes most to non-lfs repo weight. But now I wonder: Does a script like that exist already?