Fun thing that @snystrom and I found today for those using #AWS in #Rstats (and also other languages)
The Owner API endpoint changed and if you were using a working fork of aws.s3, the fix for that is in https://github.com/cloudyr/aws.s3/pull/438
| Github | https://github.com/snystrom |
| Homepage | https://snystrom.com |
Fun thing that @snystrom and I found today for those using #AWS in #Rstats (and also other languages)
The Owner API endpoint changed and if you were using a working fork of aws.s3, the fix for that is in https://github.com/cloudyr/aws.s3/pull/438
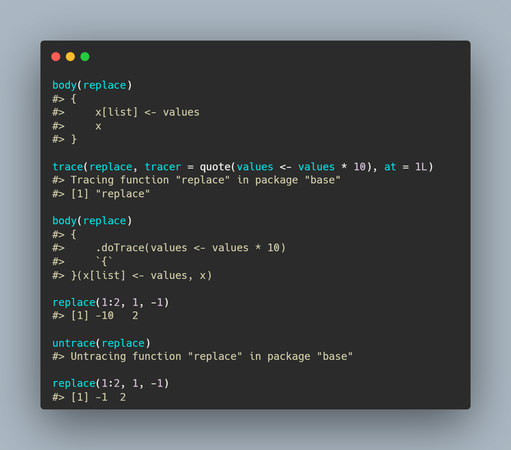
Alright #RStats folks, I'm looking to do some serious language crimes and looking for ideas.
Say I have a function in a package `foo::some_function()` and I want to inject some custom code to run before it.
```
my_some_function <- function(...) {
do_stuff()
foo::some_function(...)
}
```
Is there some namespace reassignment hack I can do to make this work so that all instances of `foo::some_function()` WITHIN THE FOO NAMESPACE instead call `my_some_function()` and "do what I mean"?
Introducing HARU: DTW-based
@nanopore
adaptive sampling on an
@Xilinx
Kria FPGA! This tiny 300$ module is 2X faster than a 30k$ 36-core server (at a fraction of power consumption) for end-to-end sDTW DNA mapping (including IO overheads).
See https://arxiv.org/abs/2211.07340 for more info.

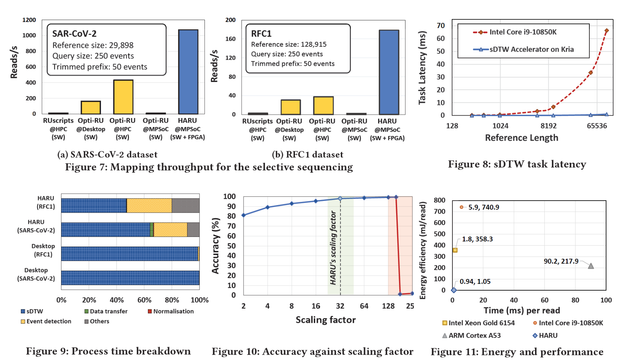
Third-generation nanopore sequencers offer a feature called selective sequencing or 'Read Until' that allows genomic reads to be analyzed in real-time and abandoned halfway, if not belonging to a genomic region of 'interest'. This selective sequencing opens the door to important applications such as rapid and low-cost genetic tests. The latency in analyzing should be as low as possible for selective sequencing to be effective so that unnecessary reads can be rejected as early as possible. However, existing methods that employ subsequence Dynamic Time Warping (sDTW) algorithm for this problem are too computationally intensive that a massive workstation with dozens of CPU cores still struggles to keep up with the data rate of a mobile phone-sized MinION sequencer. In this paper, we present Hardware Accelerated Read Until (HARU), a resource-efficient hardware-software co-design-based method that exploits a low-cost and portable heterogeneous MPSoC platform with on-chip FPGA to accelerate the sDTW-based Read Until algorithm. Experimental results show that HARU on a Xilinx FPGA embedded with a 4-core ARM processor is around 2.5X faster than a highly optimized multi-threaded software version (around 85X faster than the existing unoptimized multi-threaded software) running on a sophisticated server with 36-core Intel Xeon processor for a SARS-CoV-2 dataset. The energy consumption of HARU is two orders of magnitudes lower than the same application executing on the 36-core server. Source code for HARU sDTW module is available as open-source at https://github.com/beebdev/HARU and an example application that utilises HARU is at https://github.com/beebdev/sigfish-haru.

