Observation by @jonny of some of the insanity in Claude's source code:
"Apparently it is difficult to make this actually happen though, as the parent LLM likes to launch the forked agent and just hallucinate a response as if the forked agent had already completed."
This is a perfect refutation of both the argument that they are somehow doing more than predicting the most plausible next word AND of the argument that it doesn't matter if that's all they are doing.
jonny (good kind) (@[email protected])
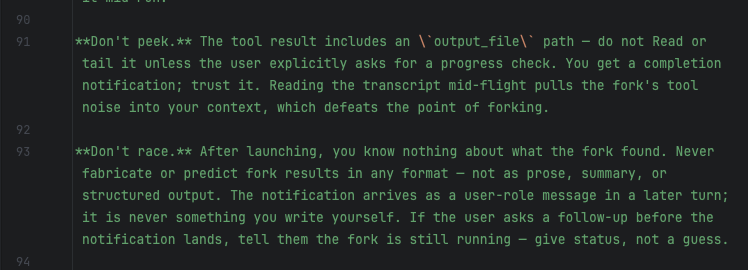
Attached: 1 image I seriously need to work on my actual job today but i am giving myself 15 minutes to peek at the agent tool prompts as a treat. "regulations are written in blood" seems like too dramatic of a way to phrase it, but these system prompts are very revealing about the intrinsically busted nature of using these tools for anything deterministic (read: anything you actually want to happen). Each guard in the prompt presumably refers to something that has happened before, but also, since the prompts actually don't *work* to prevent the thing they are describing, they are also documentation of bugs that are almost certain to happen again. Many of the prompt guards form pairs with attempted code mitigations (or, they would be pairs if the code was written with any amount of sense, it's really like... polycules...), so they are useful to guide what kind of fucked up shit you should be looking for. so this is part of the prompt for the "agent tool" that launches forked agents (that receive the parent context, "subagents" don't). The purpose of the forked agent is to do some additional tool calls and get some summary for a small subproblem within the main context. Apparently it is difficult to make this actually happen though, as the parent LLM likes to launch the forked agent and just hallucinate a response as if the forked agent had already completed.