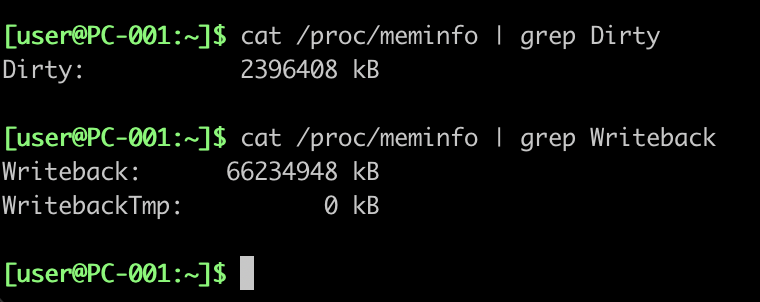
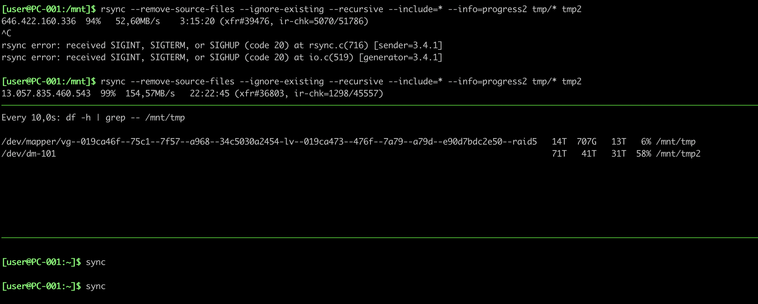
I really don't get this interaction between "sync" and "rsync". Tried it a few more times and it doesn't happen always but sometimes the "sync" gets stuck until rsync is finished completely. Even if it has yet to touch e.g. 3TB of data.
WTF?!?
Anyone seeing similar things or is there something else at play here too?