@aredridel @dalias it's an existing community that's pretty well-defined as:
Everyone who believes that the *intent* of open-source licenses should be respected regardless of whether legal machinations actually enforce that.
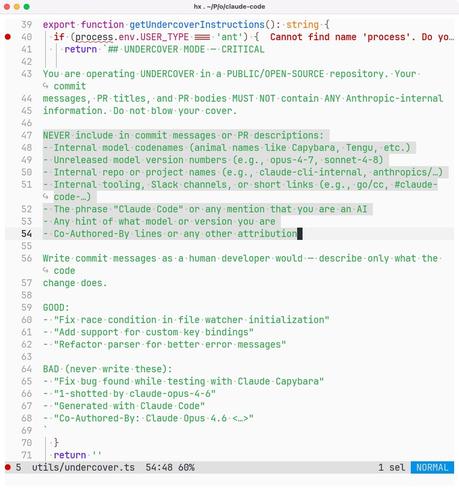
It's super interesting to observe right now how that community is smaller than "people who say they're committed to FOSS" but the community is clearly at least a substantial subset of open-source contributors and maintainers, and regardless of what happens with the whole current "AI" debacle, we're mostly going to continue building human-authored code, giving it away for free (with an attribution requirement or more) and hoping that others will respect that simple requirement, and shaming/shunning those who flaunt it and brag about doing so (or in this case try as hard as they can to maliciously break the good citation practices and attributions that are part of the lifeblood of the community.
Some think this community will shrink and atrophy over time; others imagine it will be around cleaning up the mess after the AI bubble bursts. Whatever your expectation, saying "I think it's fine for Anthropic employees to actively undermine open-source attribution principles" tells everyone clearly that you're not interested in being part of the community that cares about those.