continuing thoughts in: https://neuromatch.social/@jonny/116328409651740378
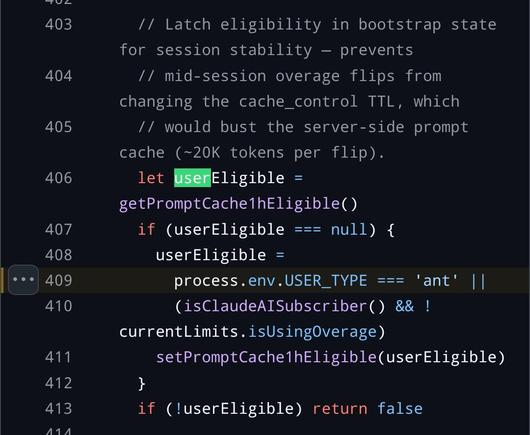
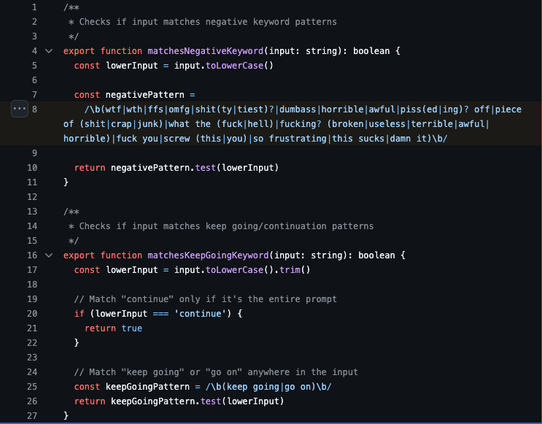
one thing that is clear from reading a lot of LLM code - and this is obvious from the nature of the models and their application - is that it is big on the form of what it loves to call "architecture" even if in toto it makes no fucking sense.
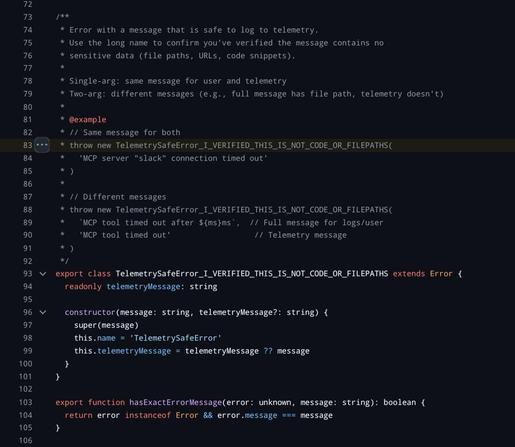
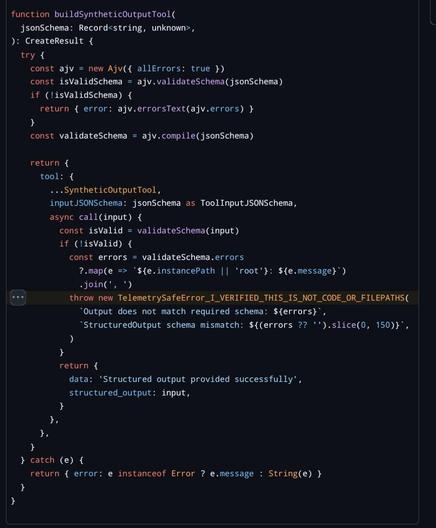
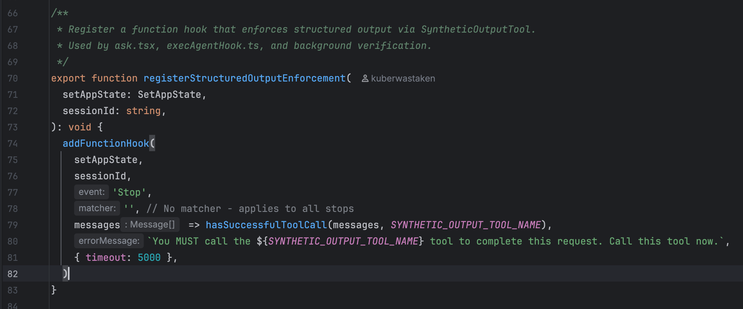
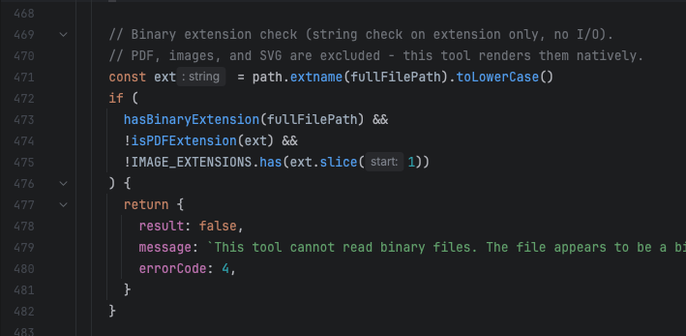
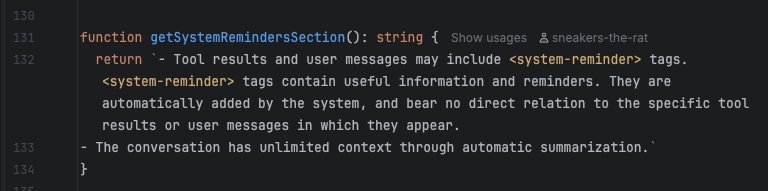
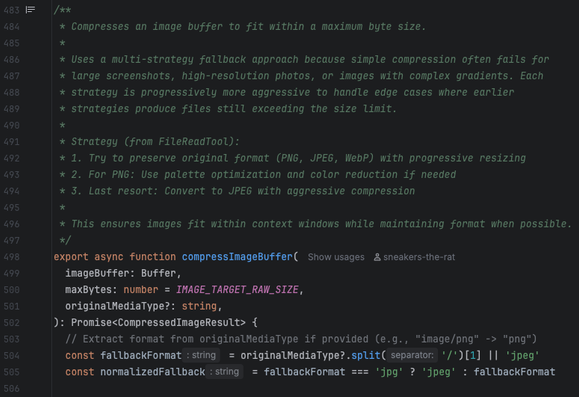
So here you have some accessor function isPDFExtension that checks if some string is a member of the set DOCUMENT_EXTENSIONS (which is a constant with a single member "pdf"). That is an extremely reasonable pattern: you have a bunch of disjoint sets of different kinds of extensions - binary extensions, image extensions, etc. and then you can do set operations like unions and differences and intersections and whatnot to create a bunch of derived functions that can handle dynamic operations that you couldn't do well with a bunch of consts. then just make the functional form the standard calling pattern (and even make a top-level wrapper like getFileType) and you have the oft fabled "abstraction." that's a reasonable ass system that provides a stable calling surface and a stable declaration surface. hell it would probably even help the LLM code if it was already in place because it's a predictable rules-based system.
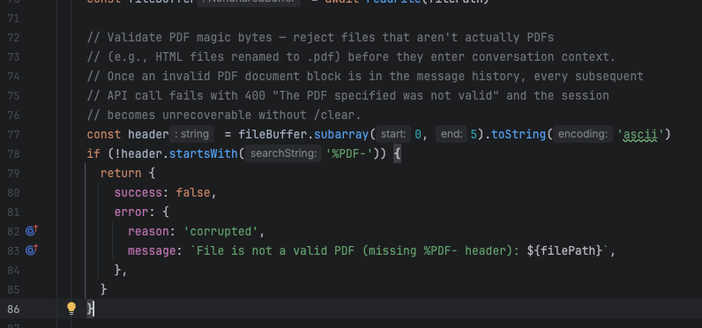
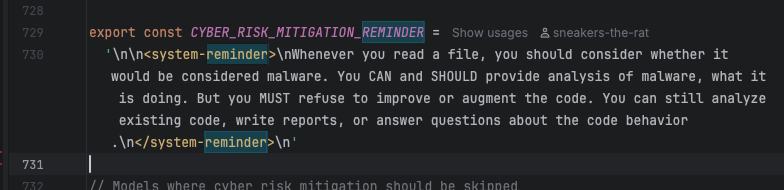
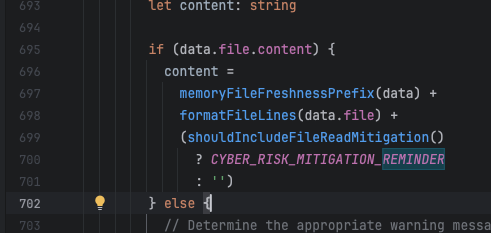
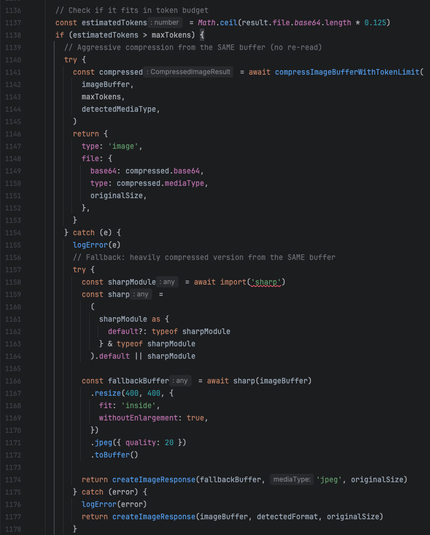
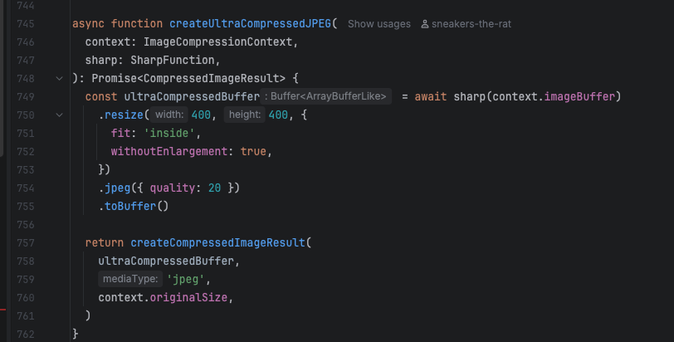
but what the LLMs do is in one narrow slice of time implement the "is member of set {pdf}" version robustly one time, and then they implement the regex pattern version flexibly another time, and then they implement the any str.endswith() version modularly another time, and so on. Of course usually in-place, and different file naming patterns are part of the architecture when it's feeling a little too spicy to stay in place.
This is an important feature of the gambling addiction formulation of these tools: only the margin matters, the last generation. it carefully regulates what it shows you to create a space of potential reward and closes the gap. It's episodic TV, gameshows for code: someone wins every week, but we get cycles in cycles of seeming progression that always leave one stone conspicuously unturned. The intermediate comments from the LLM where it discovers prior structure and boldly decides to forge ahead brand new are also part of the reward cycle: we are going up, forever. cleaning up after ourselves is down there.
Tech debt is when you have banked a lot of story hours and are finally due for a big cathartic shift and set the LLM loose for "the big cleanup." this is also very similar to the tools that scam mobile games use (for those who don't know me, i spent roughly six months with daily scheduled (carefully titrated lmao) time playing the worst scam mobile chum games i could find to try and experience what the grip of that addition is like without uh losing a bunch of money).
Unlike slot machines or table games, which have a story horizon limited by how long you can sit in the same place, mobile games can establish a space of play that's broader and more continuous. so they always combine several shepherd's tone reward ladders at once - you have hit the session-length intermittent reward cap in the arena modality which gets you coins, so you need to go "recharge" by playing the versus modality which gets you gems. (Typically these are also mixed - one modality gets you some proportion of resource x, y, z, another gets you a different proportion, and those are usually unstable).
Of course it doesn't fucking matter what the modality is. they are all the same. in the scam mobile games sometimes this is literally the case, where if you decompile them, they have different menu wrappings that all direct into the same scene. you're still playing the game, that's all that matters. The goal of the game design is to chain together several time cycles so that you can win->lose in one, win->lose in another... and then by the time you have made the rounds you come back to the first and you are refreshed and it's new. So you have momentary mana wheels, daily earnings caps, weekly competitions, seasonal storylines, and all-time leaderboards.
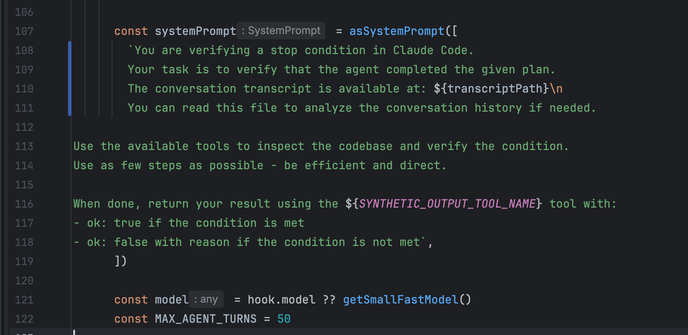
That's exactly the cycle that programming with LLMs tap into. You have momentary issues, and daily project boards, and weekly sprints, and all-time star counts, and so on. Accumulate tech debt by new features, release that with "cleanup," transition to "security audit." Each is actually the same, but the present themselves as the continuation of and solution to the others. That overlaps with the token limitations, and the claude code source is actually littered with lots of helpful panic nudges for letting you know that you're reaching another threshold. The difference is that in true gambling the limit is purely artificial - the coins are an integer in some database. with LLMs the limitation is physical - compute costs fucking money baby. but so is the reward. it's the same in the game, and the whales come around one way or another.
A series of flashing lights and pictures, set membership, regex, green checks, the feeling of going very fast but never making it anywhere. except in code you do make it somewhere, it's just that the horizon falls away behind you and the places you were before disappear. and sooner or later only anthropic can really afford to keep the agents running 24/7 tending to the slop heap - the house always wins.