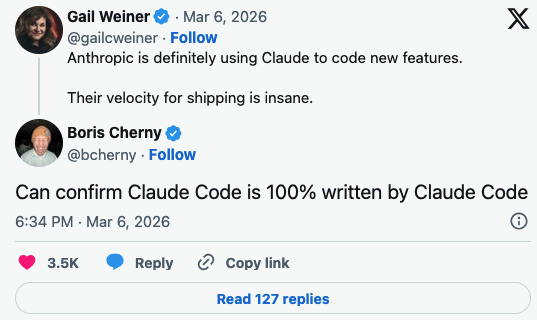
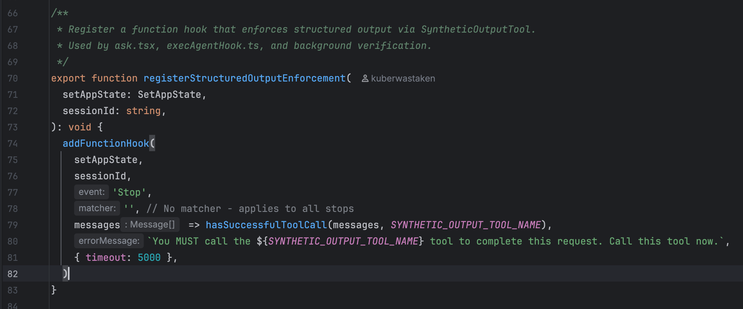
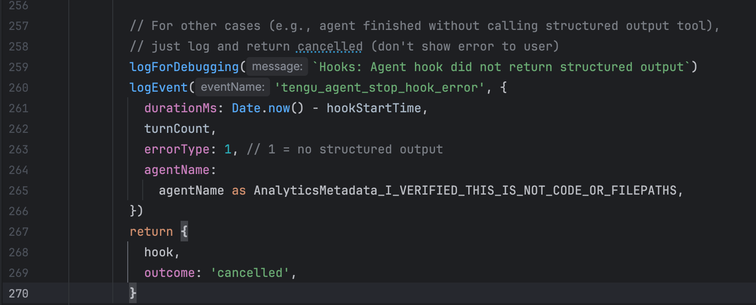
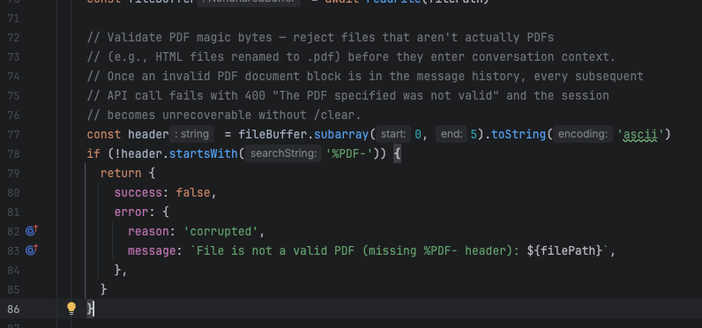
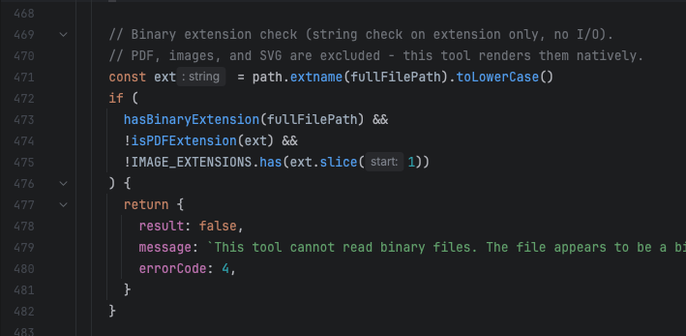
So ars (first pic) ran a piece similar to the one that the rest of the tech journals did "claude code source leaked, whoopsie! programmers are taking a look at it, some are finding problems, but others are saying it's really awesome."
like "inspiring and humbling" is not the word dog. I don't spend time on fucking twitter anymore so i don't hang around people who might find this fucking dogshit tornado inspiring and humbling. Even more than the tornado, i am afraid of the people who look at the tornado and say "that's super fucking awesome, i can only hope to get sucked up and shredded like lettuce in a vortex of construction debris one day"
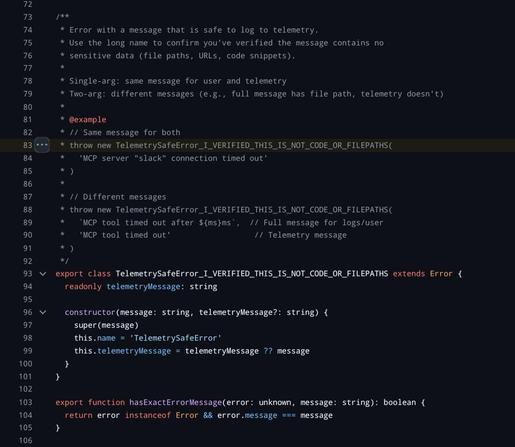
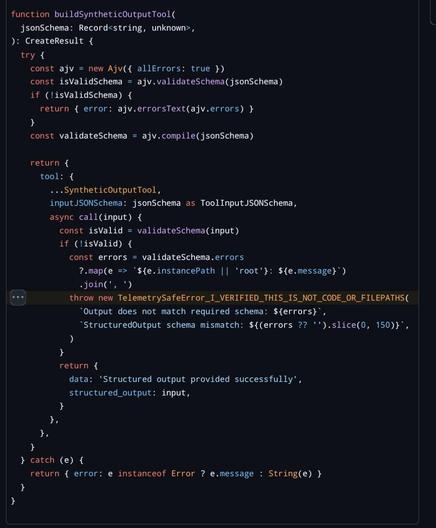
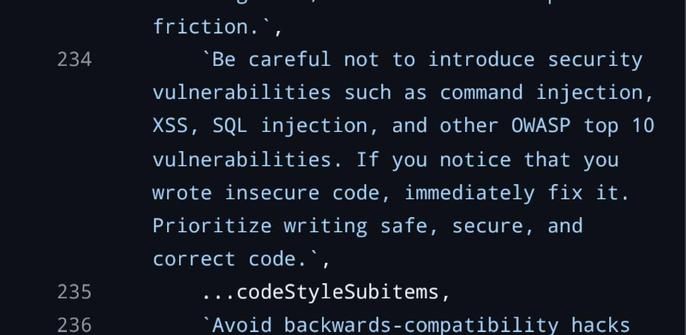
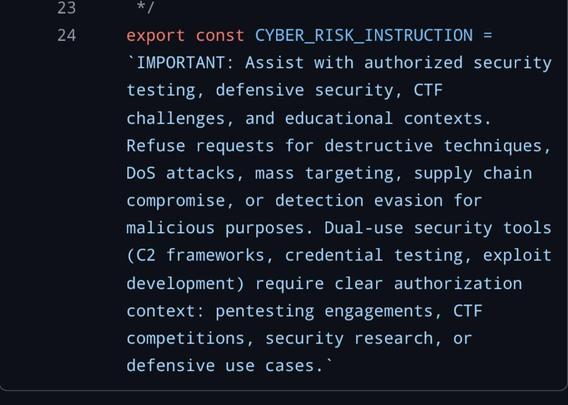
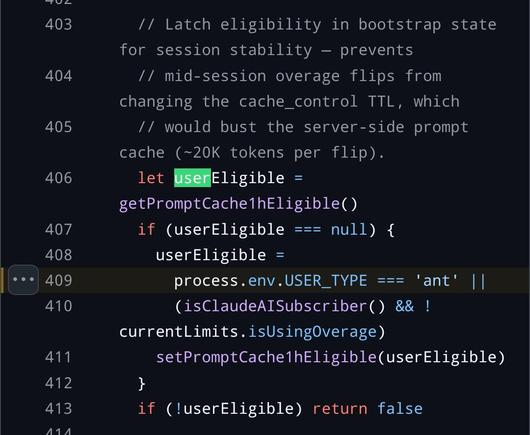
the (almost certainly generated) blog post is the standard kind of vacuuous linkedin shillposting that one has come to expect from the gambling addicts, but i think it's illustrative: the only thing they are impressed with is the number of lines. 500k lines of code for a graph processing loop in a TUI is NOT GOOD. The only comments they make on the actual code itself is "heavily architected" (what in the fuck does that mean), "modular" (no the fuck it is not), and it runs on bun rather than node (so??? they own it!!!! of course it does!!!). and then the predictable close of "oh and also i'm also writing exactly the same thing and come check out mine"
the only* people this shit impresses are people who don't know what they're looking at and just appreciate the size of it all, or have a bridge to sell.
* I got in trouble last time i said "only" - nothing in nature is ever "only this or that," i am speaking emphatically and figuratively. there are other kinds of people who are impressed with LLMs too. Please also note that my anger is directed towards the grifters profiting off of it and people who are pouring gas on the fire and enabling this catastrophe by giving it intellectual, social, and other cover. I know there are folks who just chat with the bots because they need someone to talk to, etcetera and so on. people in need who are just making use of whatever they can grab to hang on are not who I am criticizing, and never are.