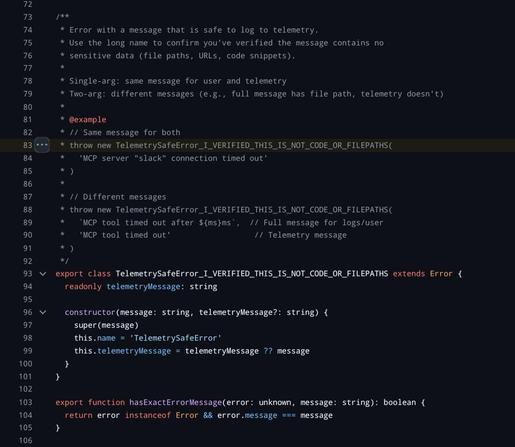
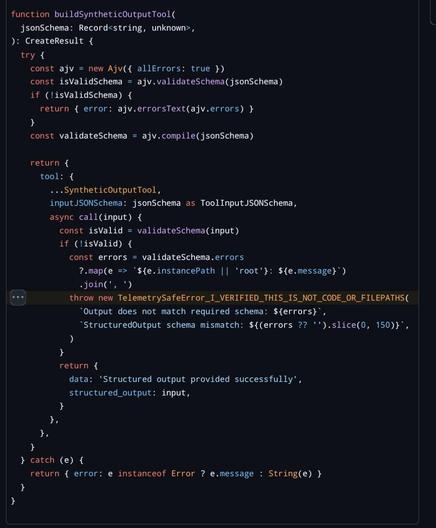
So the reason that Claude code is capable of outputting valid json is because if the prompt text suggests it should be JSON then it enters a special loop in the main query engine that just validates it against JSON schema (it looks like the schema just validates that something in fact and object and its keys are strings) and then feeds the data with the error message back into itself until it is valid JSON or a retry limit is reached.
This code is so eye wateringly spaghetti so I am still trying to see if this is true, but this seems to be how it not only returns json to the user, but how it handles all LLM-to-JSON, including internal output from its tools. There appears to be an unconditional hook where if the JSON output tool is present in the session config at all, then all tool calls must be followed by the "force into JSON" loop.
If that's true, that's just mind blowingly expensive
edit: please note that unless I say otherwise all evaluations here are just from my skimming through the code on my phone and have not been validated in any way that should cause you to be upset with me for impugning the good name of anthropic
edit2: this is both much worse and not as bad as i thought on first read - https://neuromatch.social/@jonny/116326861737478342