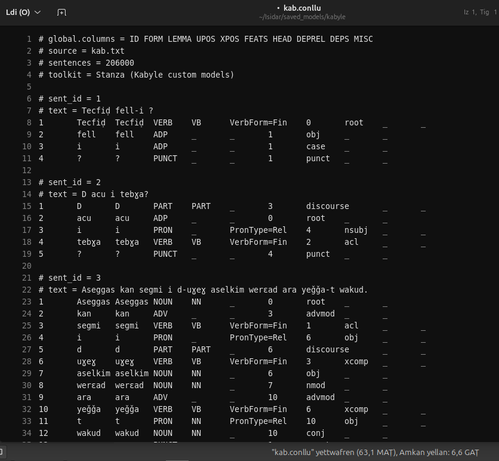
Analyse automatique d'une phrase en #kabyle.
Est-ce correct ?
Si les humains ne savent pas répondre, ne compte pas sur l'iya :D
Phrase : Yegzem tasa-w mi t-walaɣ.
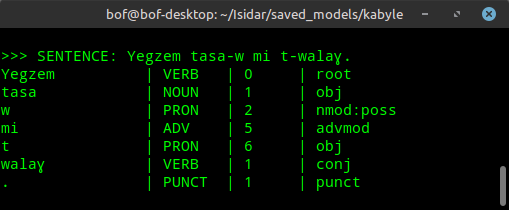
Analyse automatique d'une phrase en #kabyle.
Est-ce correct ?
Si les humains ne savent pas répondre, ne compte pas sur l'iya :D
Phrase : Yegzem tasa-w mi t-walaɣ.
Du coup, je suis entrain de taguer non pas une seule phrase mais 206 000 phrases.
Le résultat final sera un corpus en kabyle taggué, certes pas à 100% correct, mais il serait possible de choisir des phrases et corriger les étiquettes.
Exemple si un verbe est taggué comme étant un nom alors, *il suffit* de modifier.
Je dis "il suffit" : qui le fera :D ?
Bref, ce n'est qu'un début.
Je viens de tagguer 10 000 phrases.
Temps estimé restant : 1h20 minutes pour tagguer mes 206 000 phrases.
Ensuite tu prends un couteau, tu fais comme ça avec la lame  , sur le corpus, et tu coupe un morceau à mettre sous ton "microscope" pour l'étudier.
, sur le corpus, et tu coupe un morceau à mettre sous ton "microscope" pour l'étudier.
Alors résultat :
Total time: 1:33:01
Processed: 206,000 sentences
Errors: 0
Speed: 36.9 sentences/second
Output: kab.conllu
Taille d'El Fichier : 63.1 Mo
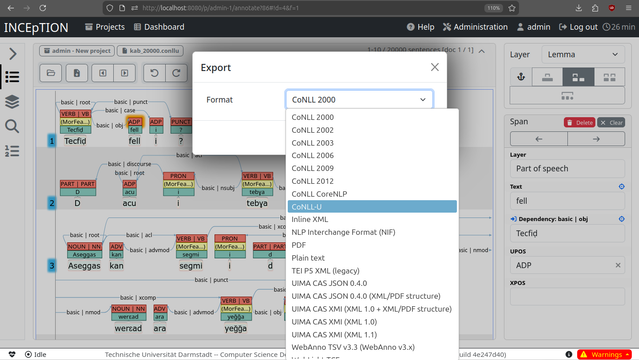
Ensuite, tu prends ce fichier, tu l'upload sur une interface web collaborative de type ArboratorGrew et tu demande à des universitaires de venir corriger les tags là où il faut.
Et tu ne trouveras aucun universitaire :D
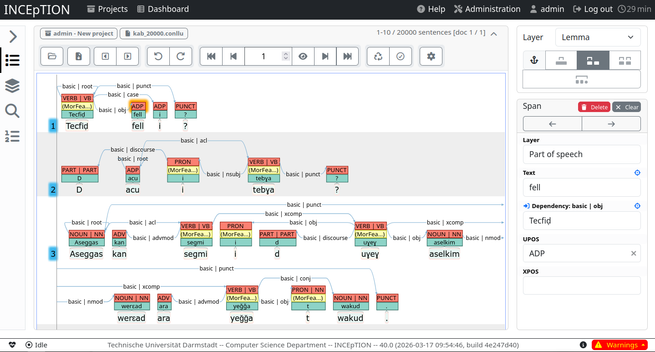
Suite : Utilisation de INCEpTION
Technische Universität Darmstadt -- Computer Science Department -- INCEpTION -- 40.0
Le logiciel INCEpTION c'est celui-ci :
Le logiciel en question permet de faire des annotations de phrases, classification de phrases, annotations d'entités etc ...
Presque tout ce qu'il faut pour un fichier CoNLLU.

Le logiciel permet de créer plusieurs utilisateurs et chacun procède collaborativement à annoter les phrases.
C'est un peu la même chose avec les plateformes de traduction : un système de rôles avec des traducteurs, des réviseurs et des admins.
Si deux annotateurs annotent de façon différente les segments d'une phrase alors un réviseur procédera à gérer le conflit d'annotation.
Le menu "Agreement" gère ce cas justement lorsque deux utilisateurs annotent de façons différentes des phrases.
Dans ce menu, il y a comme un moteur de recherche pour la gestion des conflits d'annotations.
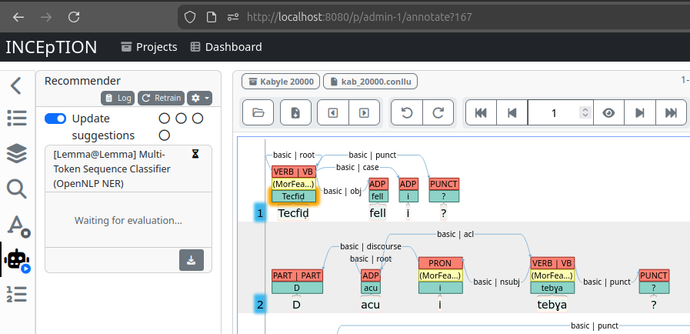
Le logiciel possède également un "algorithme" de recommandation.
Exemple : Si tu as taggué à plusieures reprises que "et" est une préposition et bien, il va te recommander l'étiquette préposition à chaque fois qu'il rencontre un "et" dans une phrase.
Pareil pour les verbes, les noms, les adverbes etc.
C'est l'icône robot à gauche et possède déjà des "Recommanders" prêts à être utilisés (pré-configurés).
Du coup, le truc le plus chiant à faire justement c'est d'annoter des phrases. Et même si elles sont déjà annotées, le plus chiants c'est de vérifier les annotations phrase par phrase loll
Personne n'osera s'aventurer là dedans :D
Sais-tu pourquoi personne n'osera s'aventurer là dedans ?
ça ne donne pas à manger. Ce n'est pas rémunéré, tout simplement.
J'ai trouvé quelques infos, en effet. Certains projets de recherche consacrent des bourses et des budgets de recherche qui s'étalent sur un certain nombre d'années.
Ça varie selon la taille du corpus, des objectifs et ça peut atteindre jusqu'à : 2 millions de dollars 😅
Ce n'est pas ButterflyOfMontagne qui va le faire alors. Il faut une volonté politique et académique.
Donc, la seule chose que je peux faire, vu que j'ai atteins ma limite, je peux uniquement publier le modèle qui permet de tagguer des phrases, tel quel, imparfait soit-il et que quelqu'un d'autre vienne, d'ici 50 ans, créer un fix et/ou un truc standardisé.
Ah bah oui, lorsque ta tête touche un plafond, faut savoir arrêter.
Juste pour te remonter le moral, c'est le cas de toutes les langues, ce n'est pas un cas particulier le kabyle.
Toutes les langues proposent de temps à autre une mise à jour de leurs treebanks afin de corriger des trucs parceque … langues vivantes, ça évolue tout le temps. Rien n'est fixe, ce ne sont pas de saintes écritures :)