I think I have a genuine need for an #LLM. Can someone tell me if this is possible?
@openbenches contains ~40k text inscriptions.
Someone wants to know how many are dedicated to men, how many to women.
"To Grandma Sylvia" is obvious.
"To R Smith" is not.
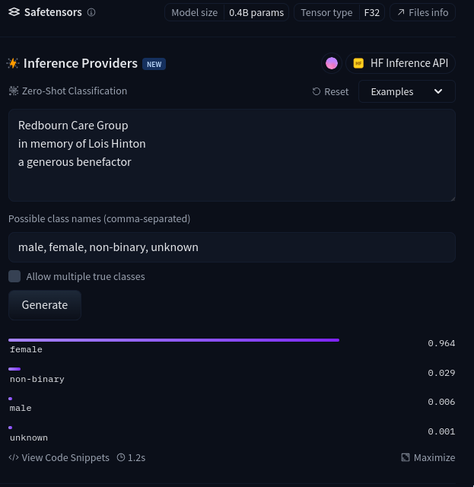
Could an AI give a rough estimate of the gender of a subject?
Could it ignore text relating to who the inscription is from? "To Granny from Dave and Alice".
What would be the most accurate / cheapest / fastest / easiest tool to work with?