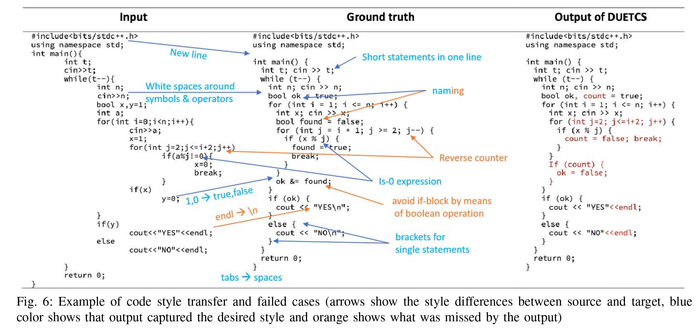
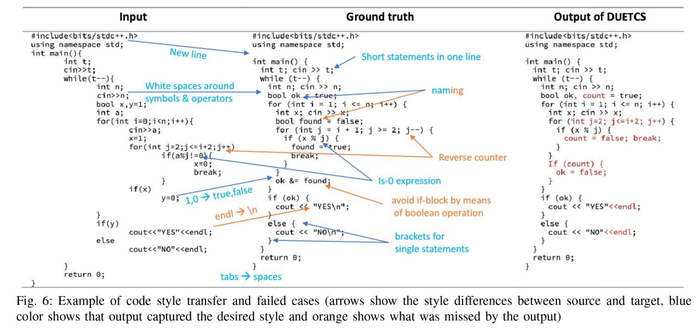
i'm at a loss of words after reading a paper about reformatting code using an ML model that has a measured statistical quantity A_c which says how often the reformatted code behaves the same as the original
the "ideal" (their choice of words) case is 64.2%
edit: this got popular without me really intending to, so here's why i'm reading research: i want a semantic style transfer tool that can automatically format a patch "the same as the rest of the file / rest of codebase is formatted" without the rigidity involved in black or rustfmt that i find so hostile to my workflow that i refuse to use them. obviously, i want a tool that generates semantically equivalent code 100.0% of time (ignoring source locations or reading from __file__)