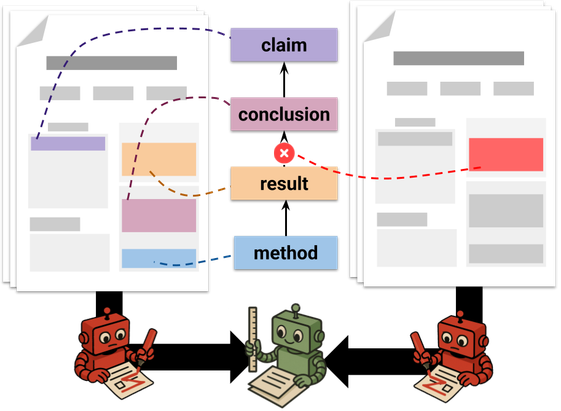
𝗔𝘂𝘁𝗼𝗺𝗮𝘁𝗶𝗰 𝗿𝗲𝘃𝗶𝗲𝘄𝗲𝗿𝘀 𝗰𝗮𝗻 𝗺𝗶𝘀𝘀 𝗳𝘂𝗻𝗱𝗮𝗺𝗲𝗻𝘁𝗮𝗹 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗲𝗿𝗿𝗼𝗿𝘀.
👀 LLM-generated reviews may look convincing — but how reliable are they in practice?
In our recent TACL paper, we introduce a 𝗰𝗼𝗻𝘁𝗿𝗼𝗹𝗹𝗲𝗱 𝗰𝗼𝘂𝗻𝘁𝗲𝗿𝗳𝗮𝗰𝘁𝘂𝗮𝗹 𝗲𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗳𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 to systematically test automatic reviewers.
𝗪𝗵𝗮𝘁 𝘄𝗲 𝗳𝗶𝗻𝗱:
📊 They rely heavily on surface-level signals
⚠️ They often miss mismatches between claims and actual results