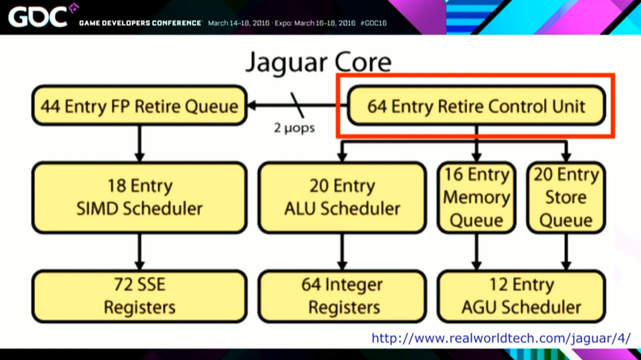
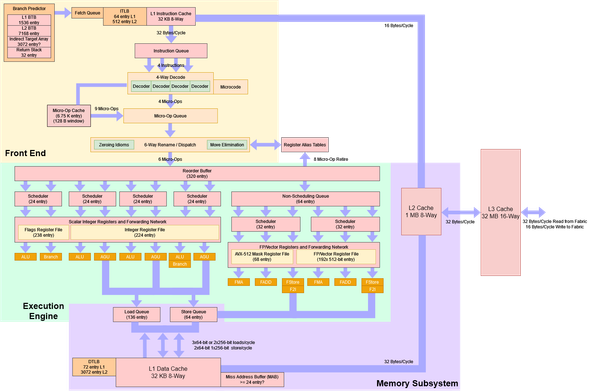
GDC 2016: "Taming the Jaguar: x86 Optimization at Insomniac Games" by Andreas Fredriksson (@deplinenoise) of Insomniac Games https://gdcvault.com/play/1023340/Taming-the-Jaguar-x86-Optimization
I thought this was really good, because it discussed CPU microarchitecture in an understandable way.
The first section was about the frontend of the chip, which is the part that fetches instructions. The Jaguar can fetch 2 instructions per cycle, which can actually be a bottleneck if you're doing a bunch of quick math on registers.
1/6