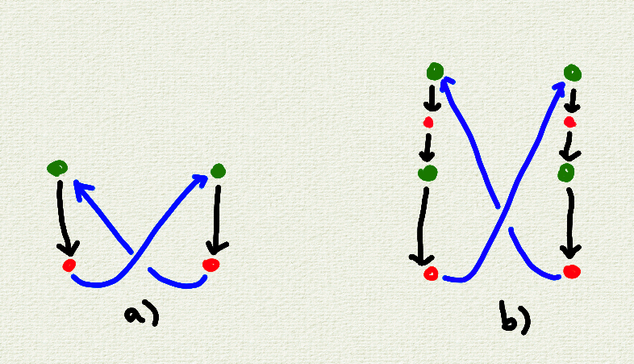
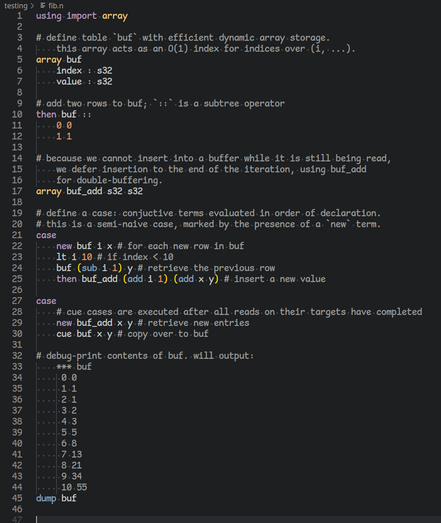
regular table insertion in nudl is performed with `then T args...`.
the language guarantees that all insertions on T are complete before all queries on T for one iteration.
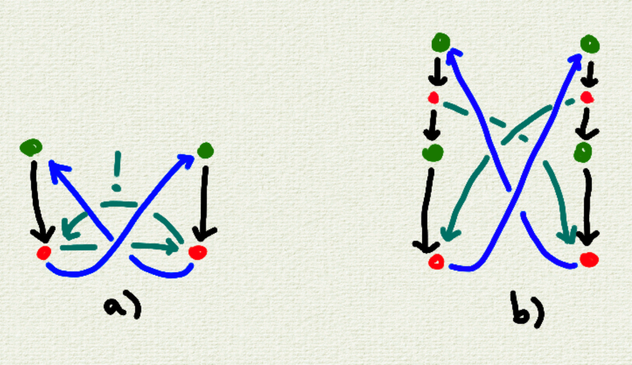
to support cyclical changes, one can `cue T args...`. this is implemented by requiring tables to buffer these changes until the end of the iteration, where they are then committed as if performed in the next iteration.
but keeping this temporary store is inefficient, and possibly unnecessary.