i've been working nonstop for so many months on the same problem that when i finally think i've solved it, it kind of triggers a state of shock, more than anything else... i think i may actually be in shock!
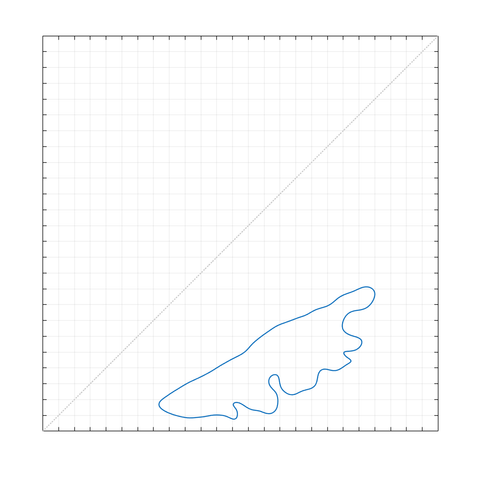
here's a preview of what i've found using this new technique... happily, this is grant work, so i will be able to publish more on these results soon! as you can see, this outline indicates the kind of shape that would be difficult to characterize using a parametric fitting method.
Still working on the writeup but I did make a slightly better plot :) the problem we had was that our data has the form of probability distribution functions over a 2D feature space from two different classes, and they have a lot of variation from subject to subject within a class, making binary classification challenging.
what contiguous regions in our 2D feature space are significantly and consistently shifted from each other between classes? i formulated a nonparametric test to answer this.
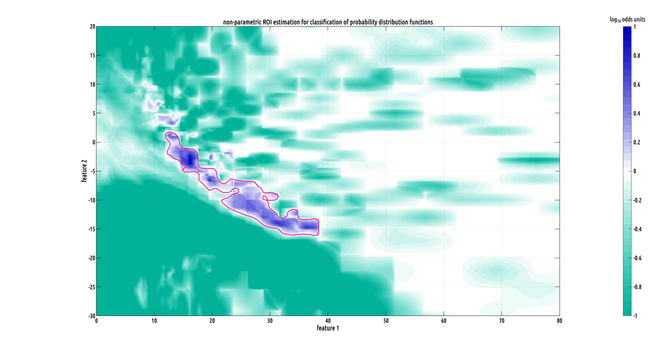
there are about 15,000 hours of electrographic recordings over roughly a 3 week period using 30 subjects going into these distribution estimates. our waveform-shape-analytic techniques extract about 100K events per hour. that way, even probabilities of relatively rare events, like 1 in 100,000, can be accurately combined into a (relatively) smooth picture such as this one.
the precision of these distribution estimates allows us to lower the effective noisefloor of the recordings. in other words, these density-functional ROIs enable us to pull highly specific signals out, that would otherwise be buried beneath the noisefloor.
that's the good news. the bad news is that the pathology we're trying to detect is sparsely represented across electrodes. so, you could have less than 30% of your subjects presenting on one electrode, but without it, your sensitivity is shot
this makes combining information across electrodes particularly interesting! happily, if all of your signals are close to 100% specific, you don't have to work too hard to combine a sparse set of them together. (e.g. the max, aka the probabilistic/fuzzy OR operator.) or, you can also use a personalized approach, by inferring which electrodes to base your prediction on for each subject, based on their features.
so, it's not something we are too worried about, although much larger datasets are required for us to better validate the results we are seeing from this initial study. hopefully, we'll be able to publish our grant report, or some aspect of it, soon...
(in case you're wondering, simply assembling the ROI features from each electrode into a standard feature matrix wouldn't be easy with this dataset because of outliers that were not homogeneous across recording channels, but that would normally be an option)
assuming that we get funding for clinical trials & get approval, we envision delivering ROIs like these to epileptologists that are unable to currently make a diagnosis with only one hour of EEG data, requiring epilepsy monitoring unit (EMU) visits for longer (3-7 day) electrographic recordings. from what our advisors are telling us, this is a big bottleneck in diagnosing epilepsy rapidly, because EMUs are backlogged and it can be a 6 month wait (or more). also, not every area has an EMU nearby.
another big need is biomarkers of epileptogenesis, prior to epilepsy onset. that's what I've been working on for the last couple of years... digital biomarkers for prediction of post-traumatic epilepsy in traumatic brain injury. we have some really interesting preclinical results, but that is an even bigger challenge than rapid epilepsy diagnosis. so, if all goes well, we hope to launch a diagnostic test first, and then a predictive test second.
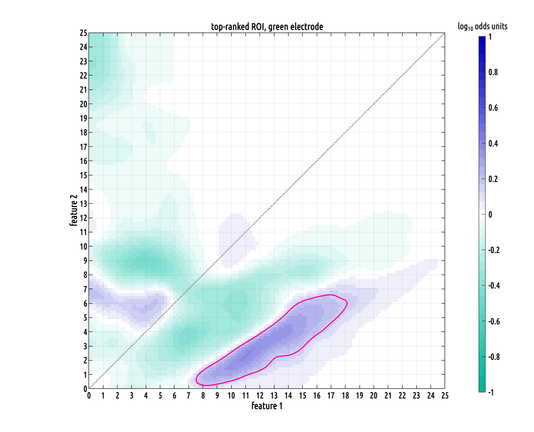
here's a really cool looking region of interest (ROI). this one is big!
the formula i came up with works in any dimension. of course, explicit density estimation rapidly breaks down with the curse of dimensionality. so, we probably can't extend this to distributions on high dimensional domains... but I can't wait to try this in 3D when I have more time :)
each subject contributes one 2D distribution to the set, so intra-class variability between proximal points in 2D can be large. one of the cool things about this nonparametric ROI test is that it has built-in robustness parameters. this means that it is capable of finding meaningful ROIs even in the presence of outliers and low sensitivity signals among the samples within groups. but, these parameters also make it difficult to visualize what data the ROIs are based on. here's a much larger area
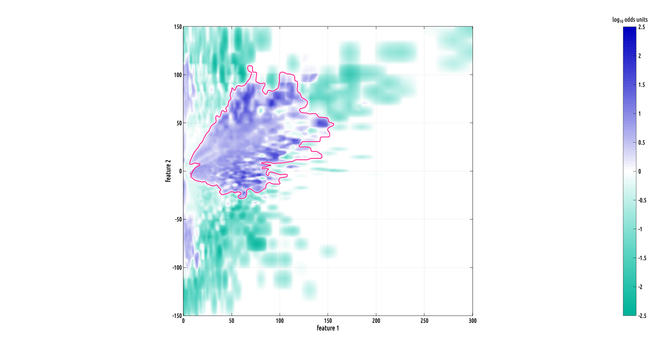
what's really interesting to me is noticing patterns in the geometry of these novel EEG biomarkers of epilepsy. it seems to me that each consistent geometric pattern in the differences of these probability distribution between classes could indicate some type of physiologically-relevant phenotype, especially when it is consistent across different studies / recordings / epilepsy types.
as someone new to the field, there is, ironically, a risk associated with being too innovative. namely, not everyone will believe your results :) that's probably been our biggest barrier to date: "the dataset is too small", or "we've seen a lot of claims to this effect, that have all proven fraudulent. how were you able to succeed?". after several years of these kinds of reactions, getting our first grant was a really big deal for us. but now that the money has run out, next steps are unclear
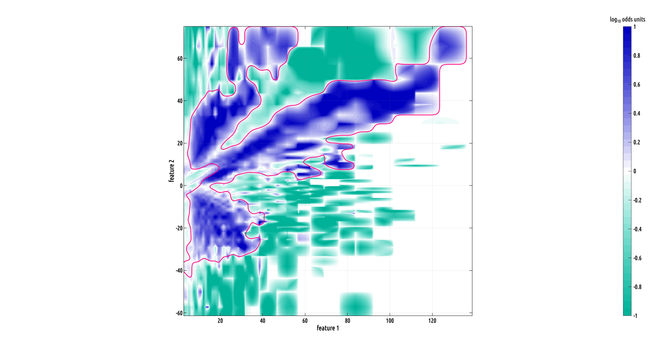
i'm still fine-tuning the design of the test. there are a lot of adjustment you can make, but in the interest of minimizing parameter number, four will hopefully be enough! this is the most specific ROI we've found for post-traumatic epilepsy in this dataset.
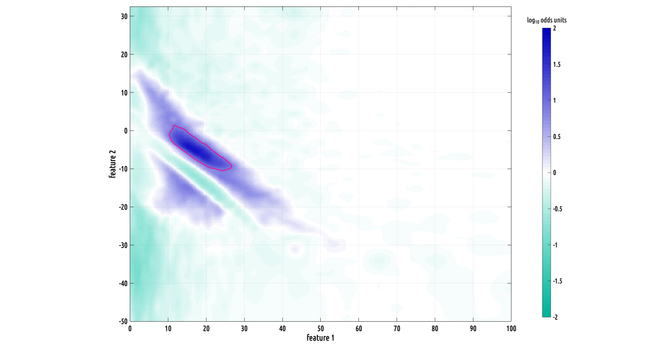
in essence, this formula allows us to infer topologic relations from topographic ones
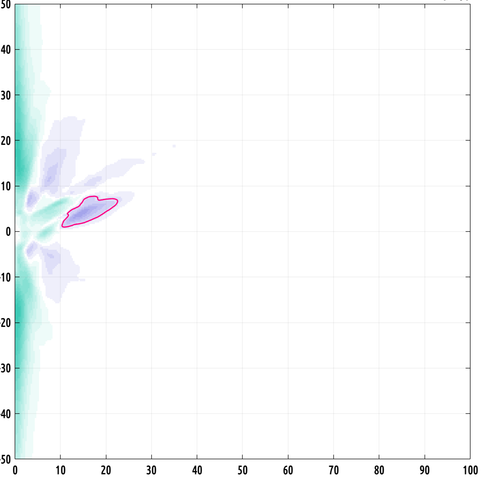
i apologize if this thread is too long, it's because i've been working on this problem for so long, that to see such beautiful pictures alongside the empirical performance evaluation results i'm seeing is such a huge validation of the 6+ years i've put into this project. #phew
in fact, these methods could not have been developed without the benefit of good visualizations. this project, if i ever get to write a book about it, is a great example of how data visualization couples with R&D work in a nice way. in fact, that's why i restricted our first application of it to 2D: that way, i knew from the get-go, that all R&D work would be backed up using nice 2D visualizations. one thing you learn through experience in data science: there are no good visualizations in 3D+
when i was first studying linear algebra, my Dad always tried to help me. but i was so, so far below his level, that most often i could not understand what he was trying to tell me. (i'm not mathematically gifted in the way that he was.)
the 2-D-first decision was a high-level decision that I made myself, based on 20+ years of experience. no business manager, MBA or otherwise, would do this.
that is a microcosm of this entire project: it's been R&D led. and i can't wait to see where it goes.
Oh, yeah, I mentioned my Dad and linear algebra. well, what he told me was that pretty much any proof in linear algebra can be extended from a 2-D proof. so, by working in 2-D, you're not really constraining yourself too much.
I think that the same is true for feature engineering. if your representation is extensible to N-D, but you haven't done the 2-D R&D work thoroughly before extending it, you're messing up.
something extraordinary happened during a work meeting yesterday. it's our weekly grant work review meeting with two of my close business partners advisors, one of whom is the PI of the grant and designed this study. as i was getting them caught up on all of the work i had done in the past week, i started to give them a live demo, and the code is now running so fast that we quickly got deep into some live R&D work via video chat. questions were flying, & hypotheses were being tested rapidly...
... even the non-technical advisor, who was technical a long long time ago (like in the 60s) before he went into management, was jumping in occasionally and asking good questions. one of his questions was what the signal was like from the ECoG electrode that was placed closest to the TBI location (a surgically induced brain lesion). our collaborators from Milan who developed this animal model of PTE gave color-codes to the 4 electrodes. ipsiperilesional: black & yellow, contra: red & green...
so, i quickly adjusted my test harness to select one electrode's worth of data before running the holdout test & computing the ROC curve & an AUC-ROC performance score. this was a test i had run many times before, but previously what i had always seen was if the positive predictions from all 4 electrodes were not pooled, high specificity could be be obtained, but not high sensitivity. as expected, the black electrode's results were not good, by itself (low AUC-ROC)...
(the "black" electrode was the one positioned closest to the TBI location.) then, i decided to re-check all 4 electrodes again, individually, since we had just checked one of them. yellow, red... and then, green. well, when we got to green, the AUC-ROC for the holdout test performance went up to .98! turned out, with all of the recent updates to the workflow that i had made, the green electrode was now outperforming the other electrodes, and combining all 4 was now holding it back. astounding...
the test samples were recorded during the first week post-TBI, during epileptogenesis (i.e. pre-epilepsy), whereas the training set was taken from recordings made 6 months later, post-epileptogenesis, after full-blown epilepsy had emerged (in a subset of the TBI+ animals). so, the signal we are trying to detect is much weaker than the signal we are training the model on, and we were able to do it with about 95% balanced accuracy using only one electrode! totally unexpected...
well, as you can imagine, we wrapped up the call pretty quickly after that! in fact, we decided that was good enough to finish the analysis work. finally! that was perhaps the most convoluted study i have ever done in terms of data wrangling and then making sense of things. but we learned so much along the way, and made so many improvements in our algorithms, because this dataset posed such extreme challenges! so, no pain no gain, i guess :) but what a load off, and what a way to end our effort!
one interesting thing about this finding is that the green channel does not show the best training performance, i.e. it does not contain the strongest diagnostic signal of PTE (post epileptogenesis). but, it does show the strongest signal for prediction of PTE, during epileptogenesis (pre PTE)! and, it's located contralaterally relative to the TBI location. so, perhaps this means that when the trauma somehow crosses the hemisphere to induce degeneration more widely, that is associated with PTE
so, the funniest/trippiest part, which really ties everything back to the first post on this thread that i made, way back in January, is that the first time i ran the holdout test, i used an ROI from the green channel that was shown in the unlabeled plot on the 2nd post in this thread, without ever looking ahead at the epoch-1 recordings. at the time, i was just guessing that this ROI would peform well, based solely on the training data. this study has such high stakes for us, so...
... i wanted to run an honest test, not only on our algorithms and software, but also on my own ability to tell when we have found a biologically relevant signal. this is another place where the 2D visualizations become essential: you need to have a background in biology to determine plausibility of a novel signal, and that's something i specialize in. and, you only get one shot at a no-lookahead holdout test: once you've run it, any subsequent tests could be biased by what you've learned...
... back in January, I had selected this one ROI from the green channel based on a combination of training performance and biological plausibility, and i was able to see a predictive signal when i ran the no-lookahead holdout test. that was a great moment, but then came the hard work of automating the entire workflow so that this ROI could be identified without me hand-picking it, based on my own subjective judgement. so...
... imagine my surprise when i saw almost exactly the same ROI appear from yesterday's results using an automated system restricted to the green channel! guess who's baaaack :) but now i can show you a better plot, overlaid onto the heatmap used by the nonparametric ROI test i formulated to help us identify these subtle shifts in probability mass between the TBI+, PTE- and TBI+, PTE+ groups.