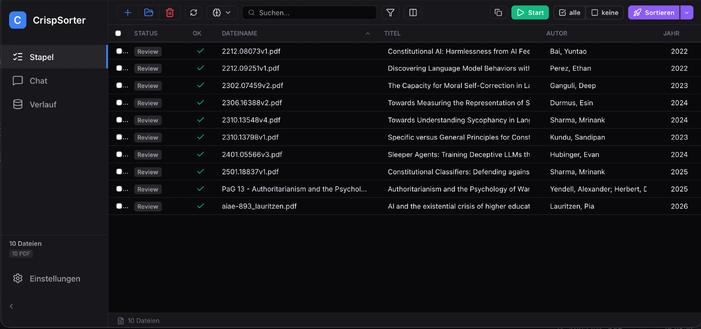
If you download hoards of documents daily, and could use them automatically sorted, here is a tool you might find useful:
an AI-powered document organiser. Drop in a bunch of PDFs or DOCX files — it extracts Document Text, identifies Title, Author, & Year from each, & sorts them structured.