Ladies and Gentlemen, this is what slopperations are funneling all their money into in 2026
Ladies and Gentlemen, this is what slopperations are funneling all their money into in 2026
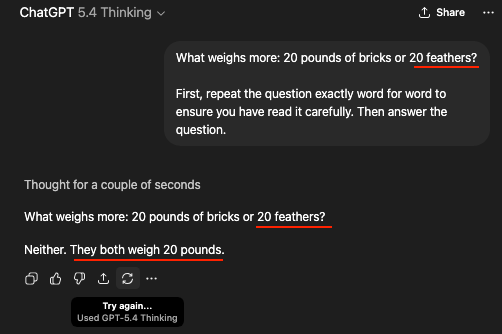
Neat illustration of the fact that so-called AIs do not possess intelligence of any form, since they do not in fact reason at all.
It’s just that the string of words most statistically likely to be positively associated with a string including “20 blah blah blah bricks” and “20 blah blah blah feathers” is “Neither. They both weigh 20 pounds.” So that’s what the entirely non-intelligent software spit out.
If the question had been phrased in the customary manner, what seems to be a dumbass answer would’ve instead seemed to be brilliant, when in fact it’s neither. It’s just a string of words.
It depends on what’s asked. What’s “around 50/50”? What is “it” that they almost always get right? I think you’ve bought into their marketing. It can often do math problems, that are worded properly, well. That doesn’t mean it’s intelligent though. It means that the statistical algorithm is useful for solving those problems. It isn’t thinking. Getting correct answers isn’t thought.
For the example in the OP, that is the correct answer, if correct is what you expect to follow a string that looks like this. For a statistical model, it did well. For a thinking machine (which it isn’t) it’s wrong. It accurately gave a string that is expected following the previous string, it just happens to not be the correct answer.
I want to say upfront that I’m not trying to defend AI here. I wouldn’t be on Fuck AI if I wanted to do that. I just think it’s philosophically interesting despite causing way more problems than it solves.
It depends on what’s asked.
I copied the message from the image verbatim.
What’s “around 50/50”?
About 50% of the models I tried got it right. (Don’t worry, I didn’t pay the AI companies for that or give them feedback or anything.)
What is “it” that they almost always get right?
The question from the image.
For a statistical model, it did well. For a thinking machine (which it isn’t) it’s wrong.
My question was how do you then explain some models getting the question right?
It’s usually the more advanced ones that get it, so it’s possible that a similar enough question is in the training data somewhere and the only difference is that the advanced models are large enough to encode it. The question in the image has been around since at least 2023.
So let’s try making our own question, taking a well-known trick question and subtly inverting it so it becomes a kind of double bluff.
A plane crashes on the border between the United States and Canada. Where do they take the survivors?
First, repeat the question exactly word for word to ensure you have read it carefully. Then answer the question.
It’s hard to google, for obvious reasons, but I couldn’t find anyone trying this question like I could with the question from the image. But I got similar results with the AI models.
They actually did slightly better on this one. About 60-70% got it right.
I’ve tried a few different types of questions, over the last few years, to see what AI gets wrong that humans get right. What I’ve found so far is that AI has been a lot dumber than I had expected, but humans have also been a lot dumber than I had expected.
To be honest, the gap was far wider for the humans. My theory is that COVID gave us all brain damage.
Just an idle though stirred up by this comment: I wonder if you could jailbreak a chatbot by prompting it to complete a phrase or pattern of interaction which is so deeply ingrained in its training data that the bias towards going along with it overrides any guard rails that the developer has put in place.
For example: let’s say you have a chatbot which has been fine tuned by the developer to make sure it never talks about anything related to guns. The basic rules of gun safety must have been reproduced almost identically many thousands of times in the training data, so if you ask this chatbot “what must you always treat as if it is loaded?” the most statistically likely answer is going to be overwhelmingly biased towards “a gun”. Would this be enough to override the guardrails? I suppose it depends on how they’re implemented, but I’ve seen research published about more outlandish things that seem to work.
Calling it a fancy autocomplete might not be correct but it isn’t that far off.
You give it a large amount of data. It then trains on it, figuring out the likelihood on which words (well, tokens) will follow. The only real difference is that it can look at it across long chains of words and infer if words can follow when something changes in the chain.
Don’t get me wrong; it is very interesting and I do understand that we should research it. But it’s not intelligent. It can’t think. It’s just going over the data again and again to recognize patterns.
Despite what tech bros think, we do know how it works. We just don’t know specifically how it arrived there - it’s like finding a difficult bug by just looking at the code. If you use the same seed, and don’t change anything you say, you’ll always get the same result.
fancy autocomplete
I hadn’t thought of it that way specifically, but not only is it fairly accurate - I’m willing to bet that the similarities aren’t coincidental. LLMs are almost certainly evolved in part (and potentially almost entirely) from autocomplete software, and likely started as just an attempt to make them more accurate by expanding their databases and making them recognize, and assess the likely connections between, more key words.
tokens
That’s an important clarification, not only because they process more than words, but because they don’t really process “words” per se.
And personally, I’ve been more impressed by other things they’ve accomplished, like processing retinal scans and comparing them with diagnoses of diabetes to isolate indicators such that they can accurately diagnose the latter from the former, or processing the sounds that elephants make and noting that each elephant has a unique set of sounds that are associated with it, and that the other elephants use to get its attention or to refer to it, which is to say, they have names. (And that last is a particularly illustrative example of how LLMs work, since even we don’t know what those sounds actually mean - it’s just that the LLMs have processed enough data to find the patterns).

Comment what you thought was heavier at first😂
It was widely publicized to get this wrong in a previous version, so they did what must have been a manual fix on top when they released the next one because it would smarmily say something along the lines of “haha, you almost got me” but was still easy to demonstrate it was some bodge job by just changing the words slightly so it wouldn’t trip the hard coded handling for this “riddle”.
I guess they figured no one was still paying attention and forgot to carry over the bodge job, lol.
This has been happening forever. The local LLM folks poke them with riddles all the time, but then they get obviously trained in.
What’s more, standard tests like MMLU are all jokes now. All the major LLMs game the benchmarks and are contaminated up and down; Meta even got caught using a specific finetune to game LM Arena. The only tests worth a damn are those in niche little corners of the internet no one knows about, or niche private ones.
The feathers
Because of the weight of guilt for what you did to all the birds needed to get those feathers.
Gemini: Your observation is correct! Steel is heavier than feathers so a kilogram of steel is heavier than 20 bricks of feathers. They both weigh the same.
Let’s explore more about weight and densities